Tracking Architektur: Cleveres Setup für smarte Datenflüsse
Du hast AnalyticsAnalytics: Die Kunst, Daten in digitale Macht zu verwandeln Analytics – das klingt nach Zahlen, Diagrammen und vielleicht nach einer Prise Langeweile. Falsch gedacht! Analytics ist der Kern jeder erfolgreichen Online-Marketing-Strategie. Wer nicht misst, der irrt. Es geht um das systematische Sammeln, Auswerten und Interpretieren von Daten, um digitale Prozesse, Nutzerverhalten und Marketingmaßnahmen zu verstehen, zu optimieren und zu skalieren...., Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem... und ein paar fancy Dashboards – aber deine Marketingdaten sehen trotzdem aus wie ein Unfall? Willkommen in der rauen Realität digitaler TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur. Wer 2024 noch glaubt, ein bisschen PixelPixel: Das Fundament digitaler Präzision im Online-Marketing Ein Pixel – ursprünglich ein Kofferwort aus „Picture Element“ – ist das kleinste darstellbare Bildelement auf digitalen Bildschirmen oder in digitalen Bildern. Im Online-Marketing ist „Pixel“ aber mehr als nur ein technischer Begriff aus der Bildverarbeitung: Hier steht Pixel für eine der wichtigsten, aber oft unterschätzten Technologien zur Nutzerverfolgung, Conversion-Messung und Datenerhebung. Wer... Copy&Paste reicht, hat das Spiel schon verloren. In diesem Artikel zerlegen wir die Mythen, zeigen, wie ein cleveres Tracking-Setup wirklich aussieht und wie du smarte Datenströme orchestrierst, statt planlos zu sammeln. Keine Ausreden, keine Buzzword-Soße – sondern harte Fakten, handfeste Technik und ein Setup, das deine Konkurrenz alt aussehen lässt.
- Was eine moderne TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur ausmacht – und warum sie über Erfolg oder Datenchaos entscheidet
- Die wichtigsten Komponenten: Tag Management, Consent, Data Layer und API-Integrationen
- Warum Standard-Setups dich in die Datenhölle führen – und wie du das verhinderst
- Wie du Tracking-Fehlerquellen identifizierst und ein sauberes Datenfundament schaffst
- Schritt-für-Schritt-Anleitung für ein robustes, zukunftssicheres Tracking-Setup
- Technische Best Practices zu Data Layer, Server-Side TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... und Privacy-First-Architekturen
- Wie du mit cleveren Datenflüssen AnalyticsAnalytics: Die Kunst, Daten in digitale Macht zu verwandeln Analytics – das klingt nach Zahlen, Diagrammen und vielleicht nach einer Prise Langeweile. Falsch gedacht! Analytics ist der Kern jeder erfolgreichen Online-Marketing-Strategie. Wer nicht misst, der irrt. Es geht um das systematische Sammeln, Auswerten und Interpretieren von Daten, um digitale Prozesse, Nutzerverhalten und Marketingmaßnahmen zu verstehen, zu optimieren und zu skalieren...., Marketing-Automation und Personalisierung wirklich smart verknüpfst
- Warum viele Agenturen TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... falsch aufsetzen (und wie du es besser machst)
- Die wichtigsten Tools, Frameworks und Kontrollmechanismen für nachhaltige Datenqualität
- Ein schonungsloses Fazit: Wer TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... nicht versteht, steuert sein MarketingMarketing: Das Spiel mit Bedürfnissen, Aufmerksamkeit und Profit Marketing ist weit mehr als bunte Bilder, Social-Media-Posts und nervige Werbespots. Marketing ist die strategische Kunst, Bedürfnisse zu erkennen, sie gezielt zu wecken – und aus Aufmerksamkeit Profit zu schlagen. Es ist der Motor, der Unternehmen antreibt, Marken formt und Kundenverhalten manipuliert, ob subtil oder mit der Brechstange. Dieser Artikel entlarvt das... blind
TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur ist nicht der feuchte Traum von Datennerds. Sie ist das Rückgrat jedes modernen Online-Marketings. Ohne eine intelligente, skalierbare und saubere TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur kannst du dir jedes Reporting, jede AttributionAttribution: Die Kunst der Kanalzuordnung im Online-Marketing Attribution bezeichnet im Online-Marketing den Prozess, bei dem der Erfolg – etwa ein Kauf, Lead oder eine Conversion – den einzelnen Marketingkanälen und Touchpoints auf der Customer Journey zugeordnet wird. Kurz: Attribution versucht zu beantworten, welcher Marketingkontakt welchen Beitrag zum Ergebnis geleistet hat. Klingt simpel. In Wirklichkeit ist Attribution jedoch ein komplexes, hoch... und jeden Conversion-Funnel sparen. Warum? Weil du dann nicht weißt, was wirklich funktioniert – und was nicht. Egal ob Google AnalyticsGoogle Analytics: Das absolute Must-have-Tool für datengetriebene Online-Marketer Google Analytics ist das weltweit meistgenutzte Webanalyse-Tool und gilt als Standard, wenn es darum geht, das Verhalten von Website-Besuchern präzise und in Echtzeit zu messen. Es ermöglicht die Sammlung, Auswertung und Visualisierung von Nutzerdaten – von simplen Seitenaufrufen bis hin zu ausgefeilten Conversion-Funnels. Wer seine Website im Blindflug betreibt, ist selbst schuld:..., Matomo, Adobe, Facebook PixelFacebook Pixel: Das Tracking-Genie für Performance-Marketing und Datenanalyse Der Facebook Pixel ist ein Tracking-Tool, das von Meta (ehemals Facebook) bereitgestellt wird, um das Verhalten von Nutzern auf Websites zu messen und zu analysieren. Das kleine JavaScript-Snippet ist der Schlüssel zur datengetriebenen Optimierung von Facebook- und Instagram-Kampagnen. Wer ernsthaft Conversion-Tracking, zielgerichtetes Retargeting und smarte Optimierungsstrategien fahren will, kommt am Facebook Pixel... oder 20 weitere Tools: Sie alle stehen und fallen mit einem durchdachten Tracking-Setup. Und das beginnt nicht mit dem ersten Tag, sondern mit der Architektur dahinter. Wer heute noch glaubt, dass Universal AnalyticsAnalytics: Die Kunst, Daten in digitale Macht zu verwandeln Analytics – das klingt nach Zahlen, Diagrammen und vielleicht nach einer Prise Langeweile. Falsch gedacht! Analytics ist der Kern jeder erfolgreichen Online-Marketing-Strategie. Wer nicht misst, der irrt. Es geht um das systematische Sammeln, Auswerten und Interpretieren von Daten, um digitale Prozesse, Nutzerverhalten und Marketingmaßnahmen zu verstehen, zu optimieren und zu skalieren.... und ein paar Custom Events reichen, hat spätestens 2024 verloren. Es geht um Struktur, Datenflüsse, Consent-Management, Data Layer, serverseitiges Tagging, Privacy-by-Design und eine nahtlose Integration in alle relevanten Tools. Wer das nicht kann, verdient bei jedem Marketing-Euro weniger – und merkt es meist zu spät.
Die clevere TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur entscheidet, ob deine Daten Gold wert sind oder einfach nur digitales Rauschen produzieren. Viele Unternehmen merken erst beim dritten oder vierten RelaunchRelaunch: Der radikale Neustart deiner Website – Risiken, Chancen und SEO-Fallen Ein Relaunch bezeichnet den umfassenden Neustart einer bestehenden Website – nicht zu verwechseln mit einem simplen Redesign. Beim Relaunch wird die gesamte Webpräsenz technisch, strukturell und inhaltlich überarbeitet, mit dem Ziel, die User Experience, Sichtbarkeit und Performance auf ein neues Level zu heben. Klingt nach Frischzellenkur, kann aber auch..., wie teuer ein schlechtes Tracking-Setup wirklich ist. Doppelte Conversion-Zahlen, nicht nachvollziehbare Customer Journeys, Consent-Lücken und ein Reporting, das keiner glaubt – willkommen im Alltag schlechter Tracking-Architektur. Wir zeigen dir, wie du aus diesem Chaos rauskommst. Ohne Schönfärberei, ohne Agentur-Blabla. Sondern mit Technik, die wirklich funktioniert. Es wird technisch, es wird ehrlich – und es wird Zeit, dass du TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... endlich richtig verstehst.
Moderne Tracking Architektur: Die Basis für smarte Datenflüsse
TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur ist kein Buzzword, sondern das Fundament deiner gesamten Marketing- und Analytics-Infrastruktur. Im Kern geht es um das Design der Datenflüsse: Welche Events, Nutzerinteraktionen und Systemdaten werden wie, wann und wohin übermittelt? Wer mit Copy&Paste von Pixeln und Tags arbeitet, baut ein Kartenhaus, das spätestens beim ersten Consent-Update zusammenbricht. Die Herausforderung beginnt damit, dass die Anforderungen an TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... 2024 explodiert sind: DSGVO, TTDSG, ePrivacy, Browser-Restriktionen, Consent-Banner, Adblocker und ständig neue Tool-APIs. Wer denkt, ein Google TagGoogle Tag: Das Schweizer Taschenmesser für Web-Tracking und Marketing-Integration Ein „Google Tag“ ist das zentrale, universelle Tracking-Snippet von Google, mit dem Website-Betreiber eine Vielzahl von Marketing- und Analyseplattformen aus dem Google-Kosmos steuern. Früher als „Global Site Tag“ (gtag.js) bekannt, ist der Google Tag heute das Herzstück moderner Datenintegration – von Google Analytics 4 über Google Ads bis zu Floodlight, Conversion-Tracking...Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem... Setup und ein Universal AnalyticsAnalytics: Die Kunst, Daten in digitale Macht zu verwandeln Analytics – das klingt nach Zahlen, Diagrammen und vielleicht nach einer Prise Langeweile. Falsch gedacht! Analytics ist der Kern jeder erfolgreichen Online-Marketing-Strategie. Wer nicht misst, der irrt. Es geht um das systematische Sammeln, Auswerten und Interpretieren von Daten, um digitale Prozesse, Nutzerverhalten und Marketingmaßnahmen zu verstehen, zu optimieren und zu skalieren.... Property reichen, ist technisch gesehen ein Relikt aus dem letzten Jahrzehnt.
Eine saubere TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur beginnt mit der Definition von Zielsetzungen. Welche KPIsKPIs: Die harten Zahlen hinter digitalem Marketing-Erfolg KPIs – Key Performance Indicators – sind die Kennzahlen, die in der digitalen Welt den Takt angeben. Sie sind das Rückgrat datengetriebener Entscheidungen und das einzige Mittel, um Marketing-Bullshit von echtem Fortschritt zu trennen. Ob im SEO, Social Media, E-Commerce oder Content Marketing: Ohne KPIs ist jede Strategie nur ein Schuss ins Blaue.... sind wirklich relevant? Welche Events, Conversions und Userdaten brauchst du – und welche Tools müssen diese erfassen? Danach folgt die technische Modellierung: Der Data Layer wird zum zentralen Rückgrat, in dem alle relevanten Informationen strukturiert abgelegt werden – unabhängig von den eingesetzten Tools. Der Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem... wird zur Orchestrierungsplattform, Consent-Management ist Pflicht, Server-Side Tagging wird zum neuen Standard und API-Integrationen sorgen für eine nahtlose Datenweitergabe an alle Plattformen.
Wer heute eine TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur plant, muss nicht nur an AnalyticsAnalytics: Die Kunst, Daten in digitale Macht zu verwandeln Analytics – das klingt nach Zahlen, Diagrammen und vielleicht nach einer Prise Langeweile. Falsch gedacht! Analytics ist der Kern jeder erfolgreichen Online-Marketing-Strategie. Wer nicht misst, der irrt. Es geht um das systematische Sammeln, Auswerten und Interpretieren von Daten, um digitale Prozesse, Nutzerverhalten und Marketingmaßnahmen zu verstehen, zu optimieren und zu skalieren.... denken, sondern an das gesamte Marketing-Ökosystem: Advertising, Personalisierung, Marketing AutomationMarketing Automation: Automatisierung im modernen Online-Marketing Marketing Automation ist der Versuch, den Wahnsinn des digitalen Marketings in den Griff zu bekommen – mit Software, Algorithmen und einer Prise künstlicher Intelligenz. Gemeint ist die Automatisierung von Marketingprozessen entlang der gesamten Customer Journey, vom ersten Touchpoint bis zum loyalen Stammkunden. Was nach Roboter-Werbung klingt, ist in Wahrheit der Versuch, Komplexität zu beherrschen,..., Reporting, CRMCRM (Customer Relationship Management): Die Königsdisziplin der Kundenbindung und Datenmacht CRM steht für Customer Relationship Management, also das Management der Kundenbeziehungen. Im digitalen Zeitalter bedeutet CRM weit mehr als bloß eine Adressdatenbank. Es ist ein strategischer Ansatz und ein ganzes Software-Ökosystem, das Vertrieb, Marketing und Service miteinander verzahnt, mit dem Ziel: maximale Wertschöpfung aus jedem Kundenkontakt. Wer CRM auf „Newsletter..., CDP (Customer Data Platform) und Business Intelligence. Die technische Kunst besteht darin, die Datenflüsse so zu gestalten, dass sie robust, skalierbar, datenschutzkonform und nachvollziehbar sind. Das ist kein Job für Hobby-Analysten, sondern für echte Techniker mit tiefem Verständnis für Webtechnologien, Datenmodelle und Businessprozesse.
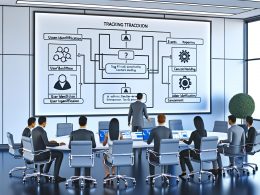
Die wichtigsten Komponenten einer zukunftssicheren Tracking Architektur
Eine starke TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur besteht aus mehr als nur ein paar Tags und Event-Listenern. Die zentralen Komponenten, die du im Griff haben musst, sind:
- Tag Management System (TMS): Tools wie Google TagGoogle Tag: Das Schweizer Taschenmesser für Web-Tracking und Marketing-Integration Ein „Google Tag“ ist das zentrale, universelle Tracking-Snippet von Google, mit dem Website-Betreiber eine Vielzahl von Marketing- und Analyseplattformen aus dem Google-Kosmos steuern. Früher als „Global Site Tag“ (gtag.js) bekannt, ist der Google Tag heute das Herzstück moderner Datenintegration – von Google Analytics 4 über Google Ads bis zu Floodlight, Conversion-Tracking...Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem..., Tealium, Adobe Launch oder Matomo Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem... übernehmen die zentrale Steuerung und Auslieferung von Tracking-Skripten. Sie ermöglichen versionierte Deployments, Debugging und rollenbasierte Verwaltung – und sind das einzige Mittel, um im Tagging-Dschungel den Überblick zu behalten.
- Data Layer: Der Data Layer ist das universelle Objektmodell, das alle relevanten Daten (z.B. Nutzerstatus, Produktinfos, Transaktionen) strukturiert bereitstellt. Ohne einen sauberen Data Layer wird dein TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... zum Flickenteppich. Mit Data Layer werden Event-Trigger, Custom Dimensions und Conversion-Events sauber und modular übergeben.
- Consent Management Platform (CMP): DSGVO-konformes TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... ist Pflicht. Eine Consent-Lösung steuert, welche Tags wann und wie feuern dürfen – und dokumentiert die Einwilligung revisionssicher. Ohne Consent-Integration drohen Abmahnungen, Bußgelder und Datenverluste.
- Server-Side TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird...: Mit Browser-Einschränkungen, Adblockern und ITP/ETP (Intelligent/Enhanced TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Prevention) wird das klassische Client-Side TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... immer unzuverlässiger. Server-Side Tagging (etwa mit Google TagGoogle Tag: Das Schweizer Taschenmesser für Web-Tracking und Marketing-Integration Ein „Google Tag“ ist das zentrale, universelle Tracking-Snippet von Google, mit dem Website-Betreiber eine Vielzahl von Marketing- und Analyseplattformen aus dem Google-Kosmos steuern. Früher als „Global Site Tag“ (gtag.js) bekannt, ist der Google Tag heute das Herzstück moderner Datenintegration – von Google Analytics 4 über Google Ads bis zu Floodlight, Conversion-Tracking...Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem... Server-Side, Matomo Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem... Server oder eigenen Proxies) holt die Kontrolle über die Daten zurück und verbessert Datenqualität, Performance und DatenschutzDatenschutz: Die unterschätzte Macht über digitale Identitäten und Datenflüsse Datenschutz ist der Begriff, der im digitalen Zeitalter ständig beschworen, aber selten wirklich verstanden wird. Gemeint ist der Schutz personenbezogener Daten vor Missbrauch, Überwachung, Diebstahl und Manipulation – egal ob sie in der Cloud, auf Servern oder auf deinem Smartphone herumlungern. Datenschutz ist nicht bloß ein juristisches Feigenblatt für Unternehmen, sondern....
- API-Integrationen: Viele Datenflüsse laufen heute über direkte API-Anbindungen zwischen Shop, CRMCRM (Customer Relationship Management): Die Königsdisziplin der Kundenbindung und Datenmacht CRM steht für Customer Relationship Management, also das Management der Kundenbeziehungen. Im digitalen Zeitalter bedeutet CRM weit mehr als bloß eine Adressdatenbank. Es ist ein strategischer Ansatz und ein ganzes Software-Ökosystem, das Vertrieb, Marketing und Service miteinander verzahnt, mit dem Ziel: maximale Wertschöpfung aus jedem Kundenkontakt. Wer CRM auf „Newsletter..., AdServern und Analytics-Plattformen. Wer den API-First-Ansatz nicht versteht, bleibt in der Copy&Paste-Hölle stecken und verliert beim Datenabgleich.
Diese Komponenten müssen wie Zahnräder ineinandergreifen. Der Data Layer liefert die Rohdaten, der Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem... orchestriert die Events, die Consent-Plattform kontrolliert, und Server-Side Tagging sichert die Datenqualität. Jede Lücke, jede fehlerhafte Implementierung und jede Inkompatibilität führen zu Datenverlust, Fehlattribution und letztlich zu falschen Entscheidungen.
Die meisten Tracking-Desaster beginnen mit Standard-Templates, Copy&Paste-Lösungen und mangelndem technischen Verständnis. Wer TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur ernst nimmt, baut eine eigene, dokumentierte und wartbare Struktur auf – nicht irgendeinen wilden Zoo aus Drittanbieterskripten.
Warum Standard-Tracking-Setups dein Marketing ruinieren
Die traurige Wahrheit: 80 Prozent aller Tracking-Setups in deutschen Unternehmen sind Flickwerke. Ein bisschen Google AnalyticsGoogle Analytics: Das absolute Must-have-Tool für datengetriebene Online-Marketer Google Analytics ist das weltweit meistgenutzte Webanalyse-Tool und gilt als Standard, wenn es darum geht, das Verhalten von Website-Besuchern präzise und in Echtzeit zu messen. Es ermöglicht die Sammlung, Auswertung und Visualisierung von Nutzerdaten – von simplen Seitenaufrufen bis hin zu ausgefeilten Conversion-Funnels. Wer seine Website im Blindflug betreibt, ist selbst schuld:... hier, ein Facebook PixelFacebook Pixel: Das Tracking-Genie für Performance-Marketing und Datenanalyse Der Facebook Pixel ist ein Tracking-Tool, das von Meta (ehemals Facebook) bereitgestellt wird, um das Verhalten von Nutzern auf Websites zu messen und zu analysieren. Das kleine JavaScript-Snippet ist der Schlüssel zur datengetriebenen Optimierung von Facebook- und Instagram-Kampagnen. Wer ernsthaft Conversion-Tracking, zielgerichtetes Retargeting und smarte Optimierungsstrategien fahren will, kommt am Facebook Pixel... dort, alles lose über den Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem... zusammengeworfen – fertig ist der Datenbrei. Das ist keine TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur, sondern Daten-Schrott. Die Folge: Inkonsistente Zahlen, doppelte oder fehlende Conversions, Consent-Verstöße, fehlende Debugging-Möglichkeiten und ein Reporting, das keiner glaubt. Der größte Fehler: Zu glauben, dass ein Standard-Setup “out of the box” für alle Anforderungen reicht.
Die Realität sieht so aus:
- Jede Website, jede App, jedes Business-Modell hat andere Events, User Flows und Datenstrukturen.
- Jeder Consent-Banner funktioniert anders und beeinflusst, welche Daten wirklich gesammelt werden.
- Adblocker, Browser-Updates und Cookie-Policies verändern das Spiel ständig.
- Standard-Implementierungen sind nicht wartbar, nicht skalierbar – und brechen beim ersten RelaunchRelaunch: Der radikale Neustart deiner Website – Risiken, Chancen und SEO-Fallen Ein Relaunch bezeichnet den umfassenden Neustart einer bestehenden Website – nicht zu verwechseln mit einem simplen Redesign. Beim Relaunch wird die gesamte Webpräsenz technisch, strukturell und inhaltlich überarbeitet, mit dem Ziel, die User Experience, Sichtbarkeit und Performance auf ein neues Level zu heben. Klingt nach Frischzellenkur, kann aber auch... zusammen.
Was du brauchst, ist ein individuelles, dokumentiertes und versioniertes Tracking-Setup, das exakt auf deine Anforderungen zugeschnitten ist. Dazu gehört ein Data Layer, der alle relevanten Daten standardisiert bereitstellt, eine Tag-Management-Lösung mit sauberem Deployment-Workflow, eine Consent-Integration, die wirklich alle Tags kontrolliert, und eine serverseitige Architektur, die Datenverluste minimiert. Alles andere ist digitales Glücksspiel – und kostet dich langfristig Umsatz, Vertrauen und Marketingeffizienz.
Wer TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur als einmalige Aufgabe sieht (“Das machen wir beim RelaunchRelaunch: Der radikale Neustart deiner Website – Risiken, Chancen und SEO-Fallen Ein Relaunch bezeichnet den umfassenden Neustart einer bestehenden Website – nicht zu verwechseln mit einem simplen Redesign. Beim Relaunch wird die gesamte Webpräsenz technisch, strukturell und inhaltlich überarbeitet, mit dem Ziel, die User Experience, Sichtbarkeit und Performance auf ein neues Level zu heben. Klingt nach Frischzellenkur, kann aber auch... mit!”), hat den Schuss nicht gehört. TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... ist ein dauerhafter Prozess, der mit jedem Marketing-Move, jedem Tool-Update und jedem rechtlichen Wechsel erneut auf den Prüfstand gehört. Wer nicht permanent nachjustiert, verliert den Anschluss – und steuert sein Unternehmen blind.
Step-by-Step: So baust du ein robustes Tracking Setup für smarte Datenflüsse
TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur ist kein Hexenwerk – aber sie erfordert Systematik, technisches Know-how und ein paar Grundprinzipien. Hier die wichtigsten Schritte, um ein wirklich smartes und nachhaltiges Tracking-Setup zu etablieren:
- 1. Zieldefinition und Event Mapping: Definiere, welche KPIsKPIs: Die harten Zahlen hinter digitalem Marketing-Erfolg KPIs – Key Performance Indicators – sind die Kennzahlen, die in der digitalen Welt den Takt angeben. Sie sind das Rückgrat datengetriebener Entscheidungen und das einzige Mittel, um Marketing-Bullshit von echtem Fortschritt zu trennen. Ob im SEO, Social Media, E-Commerce oder Content Marketing: Ohne KPIs ist jede Strategie nur ein Schuss ins Blaue...., Conversions und User-Events wirklich relevant sind. Lege ein Event-Tracking-Konzept fest, das alle Nutzerinteraktionen und Business-Ziele abdeckt.
- 2. Data Layer Modellierung: Entwickle eine strukturierte Data Layer Spezifikation (z.B. nach GTM- oder Adobe-Standard). Alle Events, Nutzer-Attribute und Transaktionsdaten werden sauber und modular im Data Layer abgelegt.
- 3. Tag Management System einrichten: Implementiere ein Tag-Management-Tool, das alle Tracking-Tags orchestriert. Arbeite mit benutzerdefinierten Variablen, Triggern und Versionierung. Vermeide Wildwuchs durch strikte Namenskonventionen und Dokumentation.
- 4. Consent Management integrieren: Implementiere eine Consent-Lösung, die wirklich alle Tags und CookiesCookies: Die Wahrheit über die kleinen Datenkrümel im Web Cookies sind kleine Textdateien, die Websites im Browser eines Nutzers speichern, um Informationen über dessen Aktivitäten, Präferenzen oder Identität zu speichern. Sie gehören zum technischen Rückgrat des modernen Internets – oft gelobt, oft verteufelt, meistens missverstanden. Ob personalisierte Werbung, bequeme Logins oder penetrante Cookie-Banner: Ohne Cookies läuft im Online-Marketing fast gar... steuert. Consent-Status muss im Data Layer verfügbar sein und jeden Tag-Trigger beeinflussen.
- 5. Server-Side Tagging aufsetzen: Verlagere möglichst viele kritische Datenflüsse auf serverseitige Infrastruktur. Reduziere Client-Side-Tracking auf das Minimum. Nutze eigene Endpunkte, um Datenverluste durch Adblocker und Browser-Restriktionen zu umgehen.
- 6. API- und Backend-Integrationen: Binde Shop, CRMCRM (Customer Relationship Management): Die Königsdisziplin der Kundenbindung und Datenmacht CRM steht für Customer Relationship Management, also das Management der Kundenbeziehungen. Im digitalen Zeitalter bedeutet CRM weit mehr als bloß eine Adressdatenbank. Es ist ein strategischer Ansatz und ein ganzes Software-Ökosystem, das Vertrieb, Marketing und Service miteinander verzahnt, mit dem Ziel: maximale Wertschöpfung aus jedem Kundenkontakt. Wer CRM auf „Newsletter..., CDP oder BI-Systeme via APIAPI – Schnittstellen, Macht und Missverständnisse im Web API steht für „Application Programming Interface“, zu Deutsch: Programmierschnittstelle. Eine API ist das unsichtbare Rückgrat moderner Softwareentwicklung und Online-Marketing-Technologien. Sie ermöglicht es verschiedenen Programmen, Systemen oder Diensten, miteinander zu kommunizieren – und zwar kontrolliert, standardisiert und (im Idealfall) sicher. APIs sind das, was das Web zusammenhält, auch wenn kein Nutzer je eine... direkt an, um redundante Datenflüsse zu vermeiden und zentrale Datenqualität sicherzustellen.
- 7. Testing & Debugging Pipeline: Baue eine Test- und Debugging-Infrastruktur mit Echtzeit-Preview, Debug-Mode, Consent-Simulatoren und automatisierten Checks. Nur so erkennst du Fehler, bevor sie teuer werden.
- 8. Dokumentation und Versionierung: Halte jede Tracking-Implementierung, jede Data Layer-Änderung und jedes Tag-Update sauber dokumentiert und versioniert fest. Nur so bleibt dein TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... auch bei Teamwechseln und Relaunches stabil.
- 9. Monitoring und Qualitätssicherung: Implementiere Monitoring-Tools, die Datenverluste, Inkonsistenzen und Consent-Fehler automatisch erkennen und melden.
- 10. Kontinuierliche Optimierung: Überprüfe dein Tracking-Setup regelmäßig auf neue Anforderungen, rechtliche Änderungen und technische Neuerungen. Passe Data Layer, Tagging und Consent laufend an.
Wer diese Schritte konsequent durchzieht, baut ein TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Setup, das nicht nur heute, sondern auch in zwei Jahren noch funktioniert. Die meisten Fehler passieren nicht bei der Technik, sondern im Prozess: Fehlende Zieldefinition, schwache Dokumentation, keine Qualitätssicherung und ein “Das machen wir später”. Wer so arbeitet, verliert – garantiert.
Technische Best Practices: Data Layer, Server-Side Tagging und Privacy-First
Die Königsdisziplin jeder TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur ist die technische Umsetzung. Hier entscheidet sich, ob deine Daten robust, skalierbar und zukunftssicher sind – oder ob du beim nächsten Browser-Update wieder bei Null anfängst. Die wichtigsten Best Practices:
- Data Layer als Single Source of Truth: Niemals direkt aus dem DOM, von Click-Events oder aus zufälligen JS-Variablen tracken. Der Data Layer muss alle relevanten Informationen zentral, sauber und dokumentiert halten – am besten objektorientiert und modular aufgebaut. Jede Änderung im Shop, CMSCMS (Content Management System): Das Betriebssystem für das Web CMS steht für Content Management System und ist das digitale Rückgrat moderner Websites, Blogs, Shops und Portale. Ein CMS ist eine Software, die es ermöglicht, Inhalte wie Texte, Bilder, Videos und Strukturelemente ohne Programmierkenntnisse zu erstellen, zu verwalten und zu veröffentlichen. Ob WordPress, TYPO3, Drupal oder ein Headless CMS – das... oder Frontend muss im Data Layer reflektiert werden, sonst gibt es Inkonsistenzen.
- Server-Side Tagging als Standard: Klassisches Client-Side TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... ist durch Adblocker, Browser-Schutz und Consent-Einschränkungen massiv unter Druck. Mit Server-Side Tagging werden die wichtigsten Events und Userdaten serverseitig verarbeitet. Vorteil: Weniger Datenverlust, bessere Performance, mehr Kontrolle. Tools wie Google TagGoogle Tag: Das Schweizer Taschenmesser für Web-Tracking und Marketing-Integration Ein „Google Tag“ ist das zentrale, universelle Tracking-Snippet von Google, mit dem Website-Betreiber eine Vielzahl von Marketing- und Analyseplattformen aus dem Google-Kosmos steuern. Früher als „Global Site Tag“ (gtag.js) bekannt, ist der Google Tag heute das Herzstück moderner Datenintegration – von Google Analytics 4 über Google Ads bis zu Floodlight, Conversion-Tracking...Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem... Server-Side, Matomo Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem... Server oder eigene Proxies sind Pflicht für fortgeschrittene TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur.
- Consent-Status im Data Layer und Tag ManagerTag Manager: Das unsichtbare Kontrollzentrum für deine Marketing-Tools Ein Tag Manager ist das Schweizer Taschenmesser moderner Webanalyse und Online-Marketing-Automatisierung. Er ermöglicht es, verschiedenste Codeschnipsel (sogenannte „Tags“) wie Tracking-Pixel, Conversion-Skripte, Remarketing-Tags oder benutzerdefinierte JavaScript-Events zentral zu verwalten – und das ganz ohne jedes Mal den Quellcode der Website anfassen zu müssen. Kurz gesagt: Der Tag Manager ist das Cockpit, aus dem...: Consent muss maschinenlesbar und jederzeit überprüfbar sein. Jeder Tag darf nur feuern, wenn der Consent aktiv ist – und das muss auch für alle Drittanbieter-Tags gelten. Consent-Änderungen müssen in Echtzeit in den Data Layer geschrieben werden.
- API-First statt Pixel-Wildwuchs: Reduziere den Einsatz von Third-Party-Pixeln. Wo möglich, nutze direkte API-Anbindungen zwischen Systemen – für ConversionConversion: Das Herzstück jeder erfolgreichen Online-Strategie Conversion – das mag in den Ohren der Marketing-Frischlinge wie ein weiteres Buzzword klingen. Wer aber im Online-Marketing ernsthaft mitspielen will, kommt an diesem Begriff nicht vorbei. Eine Conversion ist der Moment, in dem ein Nutzer auf einer Website eine gewünschte Aktion ausführt, die zuvor als Ziel definiert wurde. Das reicht von einem simplen... Reporting, Offline-Events, CRM-Integration und mehr. Das erhöht die Datenqualität und reduziert Fehlerquellen.
- Privacy-by-Design: Sammle nur Daten, die du wirklich brauchst – und nur nach gültigem Consent. Setze Anonymisierung, Pseudonymisierung und Data Minimization konsequent um. Das schützt vor Bußgeldern, erhöht Nutzervertrauen und verbessert langfristig die Datenqualität.
Ein sauberes Tracking-Setup ist nie “fertig”. Es braucht regelmäßige Audits, technisches Monitoring und eine Fehlerkultur, die Probleme schnell erkennt und löst. Wer seine TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur als statisches Projekt sieht, ist morgen schon wieder abgehängt.
Die besten Techniker bauen TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... so, dass es modular, wartbar und automatisierbar ist. Jede Änderung in Frontend, Backend oder Marketing-Stack muss schnell, nachvollziehbar und versioniert im TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... abgebildet werden – sonst ist das Setup am ersten Black Friday schon überholt.
Fazit: Tracking Architektur entscheidet über Erfolg oder Blindflug
TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... Architektur ist der zentrale Erfolgsfaktor für datengetriebenes MarketingMarketing: Das Spiel mit Bedürfnissen, Aufmerksamkeit und Profit Marketing ist weit mehr als bunte Bilder, Social-Media-Posts und nervige Werbespots. Marketing ist die strategische Kunst, Bedürfnisse zu erkennen, sie gezielt zu wecken – und aus Aufmerksamkeit Profit zu schlagen. Es ist der Motor, der Unternehmen antreibt, Marken formt und Kundenverhalten manipuliert, ob subtil oder mit der Brechstange. Dieser Artikel entlarvt das.... Wer hier schludert, zahlt einen hohen Preis – mit schlechter Datenqualität, verpassten Conversion-Chancen und teuren Fehlentscheidungen. Ein cleveres Setup für smarte Datenflüsse ist kein Nice-to-have, sondern Pflicht für alle, die digitales MarketingMarketing: Das Spiel mit Bedürfnissen, Aufmerksamkeit und Profit Marketing ist weit mehr als bunte Bilder, Social-Media-Posts und nervige Werbespots. Marketing ist die strategische Kunst, Bedürfnisse zu erkennen, sie gezielt zu wecken – und aus Aufmerksamkeit Profit zu schlagen. Es ist der Motor, der Unternehmen antreibt, Marken formt und Kundenverhalten manipuliert, ob subtil oder mit der Brechstange. Dieser Artikel entlarvt das... ernst nehmen. Wer seine Architektur im Griff hat, weiß, was wirklich funktioniert – und kann schneller, gezielter und profitabler agieren als die Konkurrenz.
Die bittere Wahrheit: Wer TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... nicht technisch, systematisch und kontinuierlich denkt, steuert sein MarketingMarketing: Das Spiel mit Bedürfnissen, Aufmerksamkeit und Profit Marketing ist weit mehr als bunte Bilder, Social-Media-Posts und nervige Werbespots. Marketing ist die strategische Kunst, Bedürfnisse zu erkennen, sie gezielt zu wecken – und aus Aufmerksamkeit Profit zu schlagen. Es ist der Motor, der Unternehmen antreibt, Marken formt und Kundenverhalten manipuliert, ob subtil oder mit der Brechstange. Dieser Artikel entlarvt das... im Blindflug. Agenturen, die dir ein “schnelles Setup” verkaufen, verkaufen in Wahrheit Datenmüll. Wer den Ernst der Lage erkennt, investiert in Architektur, Prozesse und Technik – und macht sein Unternehmen fit für die Zukunft. Alles andere ist Zeitverschwendung.