




Airbyte Workflow Orchestration Struktur: Effizienz neu definiert
Du willst deine Datenpipelines endlich so orchestrieren, dass sie nicht mehr wie ein explodiertes Open-Source-Projekt wirken? Willkommen in der Realität moderner Datenintegration, wo Airbyte den Workflow-Orchestration-Markt aufmischt – und zwar so radikal, dass die alten ETL-Dinosaurier vor Neid platzen. Hier erfährst du, warum Airbyte WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration Struktur nicht nur ein weiteres Buzzword ist, sondern deine gesamte Datenstrategie auf links dreht. Brutal ehrlich, technisch tief und garantiert ohne Märchenerzählerei.
- Was Airbyte WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration von klassischer ETL-Integration unterscheidet
- Wie Airbyte die Struktur und Verwaltung von Data Workflows revolutioniert
- Warum Modulare Orchestration und API-zentrierte Architektur alles verändern
- Die wichtigsten Komponenten: Scheduler, Worker, Temporal und mehr
- Wie Airbyte mit Kubernetes, Docker & Co. skaliert – und wo die Stolpersteine liegen
- Step-by-Step: So setzt du eine effiziente Airbyte Orchestration Pipeline auf
- Best Practices für Monitoring, Error Handling und Automatisierung
- Warum Airbyte nicht nur Open Source ist, sondern ein Orchestrierungs-Framework für die Zukunft
Die meisten Unternehmen wurschteln sich noch mit veralteten ETL-Tools durch den Datensumpf, starren verzweifelt auf endlose Cronjobs und wundern sich, warum ihre Daten-Pipelines schneller brechen als das WLAN im ICE. Airbyte WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration Struktur setzt genau hier an – und räumt gnadenlos mit den Mythen der Datenintegration auf. Wer 2024 und darüber hinaus noch an monolithischen ETL-Prozessen festhält, hat die Zeichen der Zeit verpennt. Airbyte bringt API-First-Prinzipien, modulare Architektur und moderne Orchestration auf den Tisch – und macht den Unterschied zwischen Datengräbern und echten Insights. Was das für deine Datenstrategie bedeutet und wie du Airbyte effizient ausspielst, liest du hier. Ohne Bullshit, aber mit der Technik, die wirklich zählt.
Airbyte Workflow Orchestration Struktur: Die neue API-zentrierte Realität
Airbyte WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration Struktur ist nicht einfach nur ein weiteres Konfigurations-Tool für Datenpipelines. Es ist ein Paradigmenwechsel in der Art, wie Datenflüsse orchestriert, überwacht und skaliert werden. Während klassische ETL-Prozesse auf starre, monolithische Workflows setzen und jeden Fehler gleich zum Totalschaden machen, baut Airbyte auf lose gekoppelte, API-gesteuerte Komponenten, die skalierbar, fehlertolerant und modular sind. Das Ziel: maximale Flexibilität bei minimaler Komplexität.
Im Unterschied zu traditionellen ETL-Tools – die meist auf proprietäre Schedulers, starre Step-Sequenzen und undurchsichtige Logging-Mechanismen setzen – bringt Airbyte ein offenes, API-zentriertes Orchestrierungs-Framework mit. Das bedeutet: Jeder Schritt im WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... (von der Datenextraktion über die Transformation bis zum Load) ist als eigenständiger Service implementiert und kommuniziert über klar definierte APIs. Das Resultat ist eine Architektur, die nicht nur leichter zu debuggen, sondern auch beliebig erweiterbar ist.
Der Clou liegt in der Trennung von Steuerung und Ausführung. Airbyte nutzt eine zentrale Orchestrierungs-Engine, die den eigentlichen Dataflow steuert, während die Ausführung der einzelnen Tasks von sogenannten Workern übernommen wird. Diese Worker laufen in isolierten Docker-Containern oder Kubernetes-Pods und sind dadurch nicht nur skalierbar, sondern auch vollständig voneinander entkoppelt. Das verhindert, dass ein Fehler im Extraction-Task gleich die gesamte Pipeline zum Absturz bringt – ein Segen für jede produktive Datenumgebung.
Das Herzstück der Airbyte Orchestration Struktur ist die Integration mit Temporal, einer Open-Source-Workflow-Engine, die State Management, Retry-Logik und komplexe Scheduling-Funktionen übernimmt. Temporal ermöglicht es, Workflows als langlebige, fehlertolerante Prozesse abzubilden, die auch bei Netzwerk-Aussetzern oder Container-Crashes zuverlässig weiterlaufen. Wer noch versucht, komplexe Retry-Logik mit eigenen Cronjobs oder Airflow-DAGs nachzubauen, kann sich die Zeit sparen – Airbyte und Temporal nehmen dir das ab.
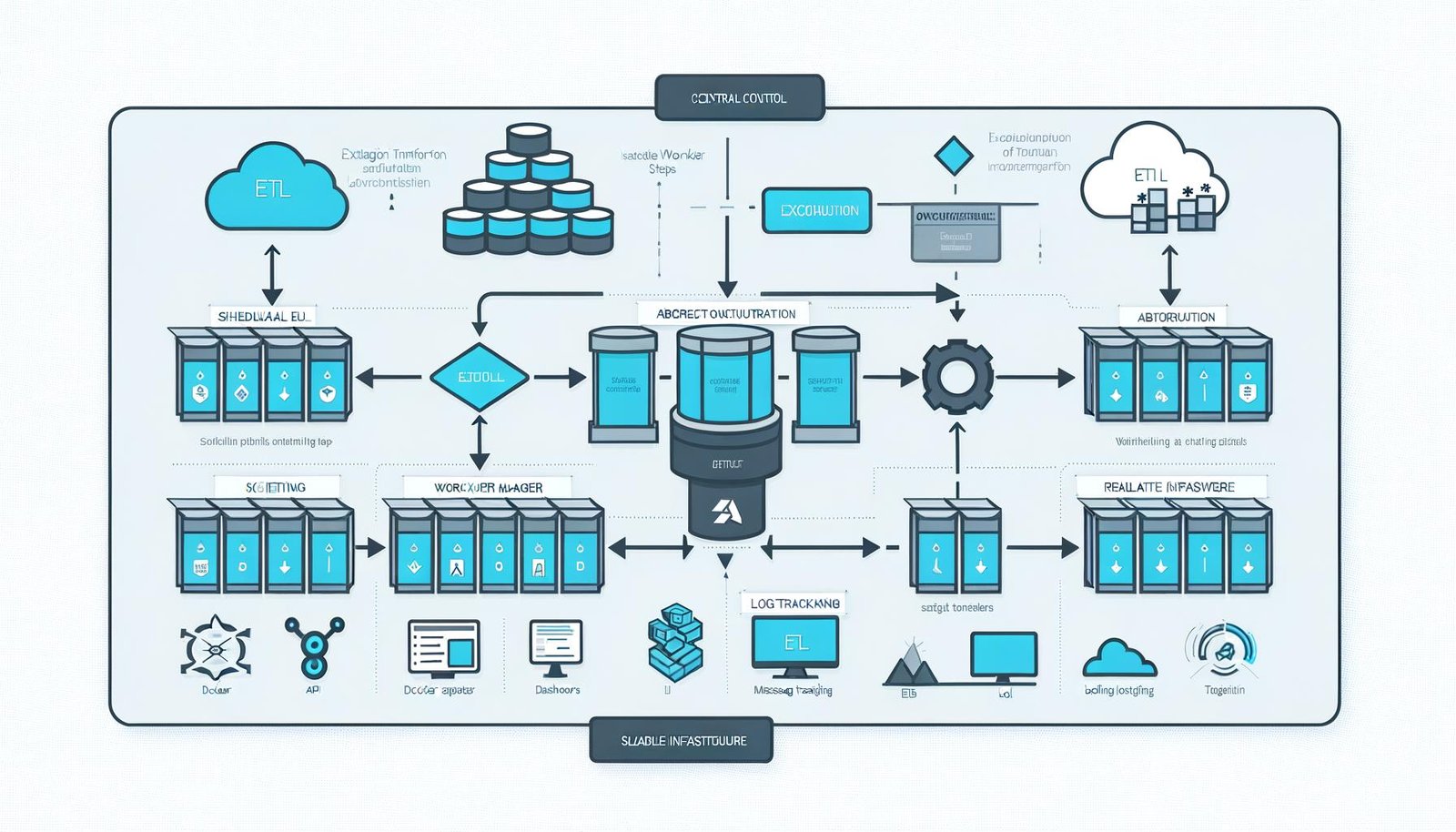
Architektur und Komponenten: Scheduler, Worker, Temporal & Co. im Detail
Wer Airbyte WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration Struktur verstehen will, muss sich die einzelnen Komponenten und deren Zusammenspiel anschauen. Im Zentrum steht der sogenannte Scheduler, der die Ausführung der Sync-Jobs verwaltet. Jeder Sync-Job besteht aus einer Reihe von Tasks (z.B. Extract, Normalize, Load), die von dedizierten Workern abgearbeitet werden. Jeder Task läuft in einem eigenen Docker-Container, was maximale Isolation und Ressourcenkontrolle ermöglicht.
Die Kommunikation zwischen Scheduler und Worker erfolgt ausschließlich über APIs und Message Queues (z.B. Postgres, Temporal, Redis), wodurch sich die Komponenten unabhängig voneinander skalieren lassen. Das ist nicht nur für große Datenvolumina entscheidend, sondern auch für Ausfallsicherheit und horizontale Skalierbarkeit. Wenn ein Worker abstürzt oder hängt, startet Airbyte automatisch einen neuen Container und setzt den Task fort – ganz ohne manuelles Eingreifen.
Temporal übernimmt das gesamte Workflow-Management. Jeder Sync-Job wird als Temporal WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ausgeführt, der aus verschiedenen Activities besteht. Diese Activities sind die einzelnen Schritte wie Datenextraktion, Transformation und Laden. Temporal sorgt dafür, dass der Status jedes Workflows jederzeit bekannt ist, und übernimmt automatisch Retries bei Fehlern, Timeout-Handling und sogar komplexe Rollbacks, wenn etwas richtig schiefgeht.
Das Monitoring erfolgt über dedizierte Dashboards, die alle Status- und Fehlercodes in Echtzeit ausgeben. Entwickler können nicht nur nachvollziehen, wo ein Fehler auftritt, sondern auch granulare Logs für jeden Task einsehen. Das ist ein massiver Unterschied zu klassischen ETL-Tools, wo Fehler oft in obskuren Logfiles oder als generischer “Job failed”-Status enden. Mit Airbyte weißt du exakt, welcher Connector, welches Mapping oder welcher Transformationsschritt den Sync abgeräumt hat – und kannst gezielt nachsteuern.
Skalierung und Automatisierung: Kubernetes, Docker und die Zukunft der Orchestration
Airbyte WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration Struktur ist von Grund auf für Skalierung gebaut. Die Kombination aus Kubernetes, Docker-Containern und stateless Services sorgt dafür, dass sich Pipelines dynamisch anpassen lassen – egal ob du zehn oder zehntausend Sync-Jobs pro Tag abfeuerst. Während die meisten alten ETL-Tools bei High-Load-Szenarien in die Knie gehen, orchestriert Airbyte seine Worker-Pods intelligent über Kubernetes Deployments und kann Ressourcen on the fly hoch- oder runterfahren.
Ein großer Vorteil der Container-basierten Architektur ist die Möglichkeit, jede Komponente unabhängig voneinander zu aktualisieren, zu überwachen und zu skalieren. Das bedeutet: Fällt ein einzelner Worker aus, bleibt der Rest der Pipeline unberührt. Neue Versionen eines Connectors oder einer Transformation lassen sich per Rolling Update deployen, ohne die gesamte Plattform zu rebooten. Continuous Deployment und Zero-Downtime-Releases werden damit zum Standard, nicht zur Ausnahme.
Automatisierung ist bei Airbyte WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration keine Option, sondern Pflicht. Sync-Jobs können per APIAPI – Schnittstellen, Macht und Missverständnisse im Web API steht für „Application Programming Interface“, zu Deutsch: Programmierschnittstelle. Eine API ist das unsichtbare Rückgrat moderner Softwareentwicklung und Online-Marketing-Technologien. Sie ermöglicht es verschiedenen Programmen, Systemen oder Diensten, miteinander zu kommunizieren – und zwar kontrolliert, standardisiert und (im Idealfall) sicher. APIs sind das, was das Web zusammenhält, auch wenn kein Nutzer je eine..., Web-UI oder CLI geplant, überwacht und ausgelöst werden. Die Integration von Webhooks, Scheduling-Optionen (z.B. Cron-ähnliche Zeitpläne) und automatisierten Retry-Strategien macht das System extrem robust. Wer auf Alerting und Monitoring setzt, kann beliebige Observability-Tools (Prometheus, Grafana, Datadog) andocken und bekommt so eine vollständige End-to-End-Überwachung der gesamten Pipeline.
Natürlich ist nicht alles Gold, was glänzt. Wer Airbyte ohne Verständnis für Kubernetes, Docker und moderne Orchestration-Patterns betreibt, landet schnell in der Komplexitätsfalle. Besonders bei Multi-Tenant-Deployments oder hochdynamischen Data-Landschaften sind solide DevOps-Kenntnisse Pflicht. Aber: Wer die Architektur einmal sauber aufsetzt, bekommt eine Plattform, die mit jedem Anwendungsfall mitwächst und selbst wildeste Data-Mesh-Träume erfüllt.
Step-by-Step: So baust du eine effiziente Airbyte Workflow Orchestration Pipeline
Airbyte WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration Struktur klingt komplex? Ist sie auch – zumindest, wenn man einfach drauflosklickt. Wer aber systematisch vorgeht, baut in wenigen Stunden eine skalierbare, fehlertolerante Pipeline auf, die jeden herkömmlichen ETL-Prozess alt aussehen lässt. Hier die wichtigsten Schritte im Überblick:
- 1. Airbyte-Installation:
Starte mit einem Docker-Compose-Setup (Single Node) oder deploye Airbyte direkt auf einem Kubernetes-Cluster für Hochverfügbarkeit. - 2. Konnektoren auswählen:
Wähle passende Source- und Destination-Connectors aus dem Airbyte-Connector-Hub. Jeder Connector läuft isoliert im eigenen Container – Flexibilität ohne Ende. - 3. Verbindungen konfigurieren:
Lege über die Web-UI oder APIAPI – Schnittstellen, Macht und Missverständnisse im Web API steht für „Application Programming Interface“, zu Deutsch: Programmierschnittstelle. Eine API ist das unsichtbare Rückgrat moderner Softwareentwicklung und Online-Marketing-Technologien. Sie ermöglicht es verschiedenen Programmen, Systemen oder Diensten, miteinander zu kommunizieren – und zwar kontrolliert, standardisiert und (im Idealfall) sicher. APIs sind das, was das Web zusammenhält, auch wenn kein Nutzer je eine... fest, welche Daten von welcher Quelle wohin synchronisiert werden sollen. Transformationen können per dbt (data build tool) integriert werden. - 4. Scheduling einrichten:
Definiere Sync-Frequenzen über die Airbyte-UI oder direkt per APIAPI – Schnittstellen, Macht und Missverständnisse im Web API steht für „Application Programming Interface“, zu Deutsch: Programmierschnittstelle. Eine API ist das unsichtbare Rückgrat moderner Softwareentwicklung und Online-Marketing-Technologien. Sie ermöglicht es verschiedenen Programmen, Systemen oder Diensten, miteinander zu kommunizieren – und zwar kontrolliert, standardisiert und (im Idealfall) sicher. APIs sind das, was das Web zusammenhält, auch wenn kein Nutzer je eine.... Flexible Zeitpläne, Event-gesteuerte Trigger oder manuelle Ausführungen sind möglich. - 5. Monitoring & Alerting aktivieren:
Kopple Airbyte an Prometheus, Grafana oder Datadog, um Metriken, Fehler und Durchsatz live zu überwachen. Alerts lassen sich für alle kritischen Events konfigurieren. - 6. Fehlerhandling automatisieren:
Nutze die eingebauten Retry- und Backoff-Strategien von Temporal, um Fehler automatisch abzufangen und zu beheben. - 7. Skalierung testen:
Simuliere Lastspitzen, indem du mehrere Sync-Jobs parallel startest. Kubernetes verteilt die Ressourcen dynamisch auf die Worker – Bottlenecks gehören der Vergangenheit an.
Wer diese Schritte konsequent durchzieht, bekommt eine Orchestration-Umgebung, die nicht nur performant, sondern auch zukunftssicher ist. Besonders für Unternehmen, die viele Datenquellen oder komplexe Transformationslogiken orchestrieren müssen, spielt Airbyte seine Stärken voll aus. Und das alles mit Open-Source-Transparenz – keine Lizenzkosten, kein Vendor-Lock-in, keine Blackbox.
Best Practices: Monitoring, Error Handling und Automatisierung in Airbyte
Eine effiziente Airbyte WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration Struktur lebt von sauberem Monitoring, robustem Fehlerhandling und maximaler Automatisierung. Wer hier schlampt, verliert schnell die Kontrolle – und damit auch die Datenqualität. Im Zentrum steht das Observability-Konzept: Alle Pipelines, Worker und Jobs müssen permanent überwacht werden, um Fehler frühzeitig zu erkennen und automatisch zu reagieren.
Das Monitoring in Airbyte basiert auf Metriken wie Job-Laufzeiten, Error Rates, Throughput und Systemauslastung. Über die Integration mit Prometheus und Grafana lassen sich Dashboards bauen, die in Echtzeit Auskunft über jeden Aspekt der Pipeline geben. Besonders wichtig: Custom Alerts für kritische Events wie Job-Abstürze, lange Laufzeiten oder wiederkehrende Fehler. Wer hier auf E-Mail-Alerts oder Slack-Notifications setzt, kann proaktiv eingreifen, bevor Daten verloren gehen.
Fehlerhandling ist in Airbyte kein nachträglicher Flickenteppich, sondern Kernbestandteil des Orchestrierungs-Frameworks. Temporal übernimmt Retries mit exponentiellem Backoff, Timeout-Management und detailliertes Error Logging. Jeder Fehler wird granular protokolliert, inklusive Stacktrace, betroffenen Daten und Task-Status. So lassen sich Ursachen schnell identifizieren und beheben – ohne tagelange Debugging-Orgie.
Automatisierung ist mehr als nur Scheduling. Airbyte unterstützt Webhooks, API-Trigger und Event-basierte AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder..., mit denen sich Pipelines vollständig in CI/CD-Workflows oder externe Event-Handler einbinden lassen. Wer regelmäßig Deployments, Datenaktualisierungen oder Schema-Änderungen orchestrieren muss, profitiert von der API-First-Philosophie: Jeder Aspekt der Plattform ist programmatisch steuerbar – ein Segen für DevOps-Teams und Dateningenieure, die Wert auf Automatisierung und Self-Service legen.
Fazit: Airbyte Workflow Orchestration Struktur als Gamechanger für moderne Datenpipelines
Die Airbyte WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration Struktur definiert Effizienz in der Datenintegration neu. Mit API-zentrierter Architektur, modularen Komponenten, Kubernetes-Skalierung und tief integrierter Fehlerbehandlung setzt Airbyte neue Maßstäbe für Datenpipelines im 21. Jahrhundert. Wer heute noch auf monolithische ETL-Tools, manuellen Cronjob-Wahnsinn und Blackbox-Lösungen setzt, verliert nicht nur Zeit und Nerven, sondern auch die Kontrolle über seine Daten – und damit den Anschluss an die Konkurrenz.
Airbyte ist mehr als nur ein Open-Source-Tool – es ist das Orchestrierungs-Framework für die datengetriebene Zukunft. Wer seine WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... Orchestration Struktur auf Airbyte aufbaut, bekommt ein System, das nicht nur skaliert, sondern sich ständig weiterentwickelt. Fehler werden transparent, Monitoring ist Standard und Automatisierung ist kein Luxus, sondern Pflicht. Kurz: Wer jetzt nicht umsteigt, bleibt im Daten-Mittelalter stecken. Willkommen in der neuen Realität der Datenorchestrierung. Willkommen bei 404.



