

Data Layer Event Konzept: So funktioniert’s im Detail
Wenn du glaubst, dass der Data Layer nur ein fancy Begriff aus der Google-Dokumentation ist, dann hast du noch nicht verstanden, wie moderne Web-Tracking-Architekturen wirklich funktionieren. Denn ohne ein durchdachtes Data Layer Event Konzept bist du blind im Daten-Dschungel – und das kostet dich nicht nur Insights, sondern auch Conversion-Optimierung, Effizienz und letztlich Geld. Es ist Zeit, den Code zu entmystifizieren, die Event-Strategie zu perfektionieren und dein Tracking auf ein neues Level zu heben. Denn in der Welt des digitalen Marketings gilt: Wer nicht misst, der nicht gewinnt – und wer keinen sauberen Data Layer hat, verliert im Stillen.
- Was ist ein Data Layer Event Konzept und warum es essentiell ist
- Die technische Funktionsweise eines Data Layers im Web
- Best Practices für die Planung und Umsetzung eines Data Layer Event Konzepts
- Wichtige Trigger, Variablen und Events im Data Layer
- Wie du dein Data Layer strukturierst, um flexible und robuste Tracking-Lösungen zu schaffen
- Tools und Techniken zum Debuggen und Validieren deiner Data Layer Events
- Häufige Fehlerquellen und wie du sie vermeidest
- Automatisierung und Wartung – damit dein Data Layer nie wieder veraltet
- Die Bedeutung eines konsistenten Data Layer Konzepts für Cross-Channel-Tracking
- Fazit: Warum ohne Data Layer Event Konzept das digitale Tracking nur eine Lotterie ist
Was ist ein Data Layer Event Konzept und warum es dein Tracking revolutioniert
Ein Data Layer Event Konzept ist die strategische Roadmap für die Events, Variablen und Trigger, die du in deinem Web-Tracking nutzt. Es ist mehr als nur eine Sammlung von Codeschnipseln – es ist das zentrale Steuerungssystem, das alle Datenflüsse innerhalb deiner Website koordiniert. Ohne dieses Konzept ist dein Tracking ein Flickenteppich aus Fragmenten, die selten miteinander harmonieren, geschweige denn valide Daten liefern. Ein durchdachtes Data Layer Konzept sorgt dafür, dass Events konsistent, nachvollziehbar und flexibel ausgelöst werden können, unabhängig davon, ob du Google Tag Manager, Tealium oder eine andere Tag-Management-Lösung nutzt.
Im Kern geht es darum, eine zentrale Datenquelle zu schaffen, die alle relevanten Nutzer-Interaktionen strukturiert erfasst. Klicks, Scroll-Events, Formularübermittlungen, Produkt-Additions – alles wird in einer einheitlichen Sprache erfasst. Das Ziel: eine klare Trennung zwischen Daten, die du sammelst, und den technischen Triggern, die sie auslösen. Damit kannst du später nicht nur bessere Reports erstellen, sondern auch komplexe Conversion- oder Funnel-Analysen durchführen, die sonst nur im Kopf der Entwickler oder im Dschungel der Logs verborgen bleiben.
Anders als bei klassischen Event-Implementierungen, bei denen du jedes Tracking individuell codierst, schafft das Data Layer Konzept eine Abstraktionsschicht. Es ist die Basis für agile, skalierbare Data-Architekturen, die sich an neue Anforderungen anpassen lassen, ohne den Code komplett umzuschreiben. Und genau das macht es zum Gamechanger – vor allem im Zeitalter der Multi-Channel-Strategien und omnichannel Customer Journeys.
Die technische Funktionsweise eines Data Layers im Web
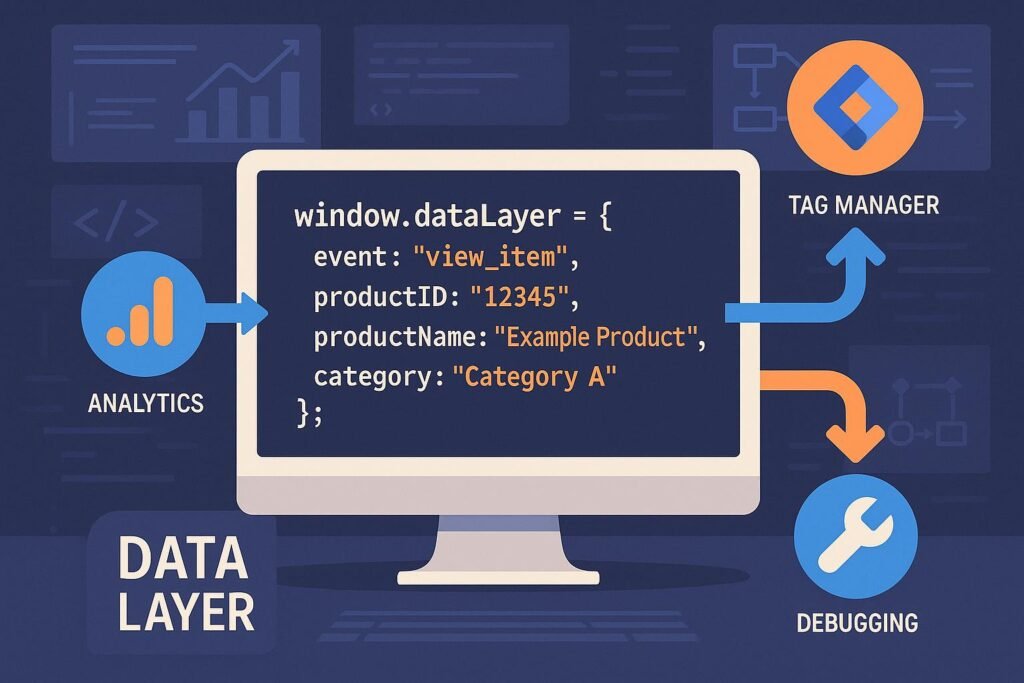
Der Data Layer ist eine JavaScript-Variable, meist ein Objekt, das alle relevanten Daten in strukturierter Form speichert. Es ist die zentrale Datenbank im Browser, die alle Nutzer-Interaktionen, Produktinformationen, Nutzerattribute und Statusmeldungen enthält. Sobald ein Event ausgelöst wird – sei es ein Klick auf einen Button, das Scrollen bis zu einem bestimmten Punkt oder eine Formularübermittlung – werden die entsprechenden Daten in den Data Layer geschrieben.
Die meisten modernen Tag-Management-Systeme greifen auf dieses Objekt zu, um dann die Daten an Analytics-Tools, Werbeplattformen oder andere Schnittstellen zu schicken. Das Ganze funktioniert in der Regel nach dem Prinzip: Der Data Layer ist der „single source of truth“ – die einzige zuverlässige Datenquelle, die alle weiteren Tools konsumieren. Das ermöglicht eine einheitliche Datenqualität und vermeidet Redundanzen sowie Inkonsistenzen.
Technisch gesehen ist der Data Layer oft eine globale Variable, z.B. window.dataLayer, die bei Seitenaufruf initialisiert wird. Bei jeder Nutzer-Interaktion wird das Objekt um spezifische Event-Daten erweitert oder aktualisiert. Dabei ist es essenziell, dass jede Änderung an dieser Datenstruktur sauber dokumentiert ist, um später nachvollziehen zu können, was wann passiert ist. Die Daten müssen klar, präzise und einheitlich formatiert sein, um im Tracking-Backend korrekt verarbeitet zu werden.
Ein Beispiel: Bei einem Produkt-Click-Event könnten im Data Layer folgende Daten gespeichert werden:
- event: „productClick“
- productID: „12345“
- productName: „SuperWidget“
- category: „Gadgets“
- price: 49.99
Dieses strukturierte Vorgehen erleichtert die spätere Auswertung enorm – und sorgt für eine saubere Verbindung zwischen Nutzerverhalten und Business-Insights.
Best Practices für die Planung und Umsetzung eines Data Layer Event Konzepts
Der erste Schritt ist, sich eine klare Datenstrategie zu erarbeiten. Was genau willst du messen? Welche KPIs sind für dein Business relevant? Welche Events müssen erfasst werden, um valide Aussagen treffen zu können? Dann folgt die technische Planung: Definiere die Datenstruktur, die Variablen, die Event-Trigger und die Verantwortlichkeiten. Nur mit einer sauberen Architektur kannst du später flexibel sein.
Hier einige bewährte Vorgehensweisen:
- Dokumentiere deine Events: Erstelle eine zentrale Übersicht aller geplanten Events, inklusive Variablen, Trigger und Zielplattformen.
- Standardisiere Datenformate: Nutze einheitliche Namenskonventionen, Datentypen und Strukturen, um Konsistenz zu gewährleisten.
- Verwende eine zentrale Datenquelle: Alle Events sollten auf einer einzigen, gut dokumentierten Data Layer-Instanz basieren.
- Automatisiere die Implementierung: Nutze Templates, Scripts und Versionierung, um Fehler zu minimieren und Wartbarkeit zu erhöhen.
- Teste intensiv: Nutze Debugging-Tools wie den GTM-Vorschau-Mode, Chrome DevTools oder spezielle Data Layer-Validatoren, um Fehler frühzeitig zu erkennen.
Der Erfolg liegt in der Disziplin: Halte dich an deine Dokumentation, überprüfe regelmäßig die Datenqualität und passe dein Konzept an neue Anforderungen an. Wichtig ist, dass dein Data Layer lebendig bleibt – es ist kein einmaliges Projekt, sondern eine kontinuierliche Weiterentwicklung.
Tools und Techniken zum Debuggen und Validieren deiner Data Layer Events
Ein sauberes Data Layer ist nur so gut wie die Kontrolle, die du darüber hast. Deshalb solltest du auf zuverlässige Tools setzen, die dir helfen, Fehler zu erkennen, Daten zu validieren und Performance-Probleme zu vermeiden. Der Google Tag Manager bietet den integrierten Vorschau-Mode, mit dem du in Echtzeit siehst, welche Events ausgelöst werden und welche Daten übertragen werden.
Zusätzlich gibt es spezialisierte Debugging-Tools wie Data Layer Inspector (Chrome-Extension), die dir eine klare visuelle Darstellung deiner Daten liefern. Mit solchen Tools kannst du einzelne Events simulieren, Variablen prüfen und Inkonsistenzen sofort erkennen. Für die Validierung der Datenqualität eignen sich auch Data Layer Validatoren, die automatisiert prüfen, ob die Daten den Vorgaben entsprechen.
Die Web-Entwickler sollten außerdem die Browser-Console nutzen, um JavaScript-Fehler, Event-Listener oder unerwartete Daten-Änderungen aufzuspüren. Bei komplexen Setups kann eine Logfile-Analyse der Server-Logs helfen, um zu sehen, ob die Daten korrekt an die Backend-Systeme übertragen werden.
Regelmäßige Audits sind Pflicht: Plane wiederkehrende Checks, automatisierte Tests und Monitoring-Lösungen ein, um sicherzustellen, dass dein Data Layer immer funktional und valide bleibt. Nur so kannst du sicherstellen, dass deine Insights zuverlässig sind und dein Tracking nicht irgendwann im Chaos versinkt.
Häufige Fehlerquellen und wie du sie vermeidest
Der größte Fehler ist das fehlende oder unzureichende Planning. Ohne klare Dokumentation und Standards driftet dein Data Layer schnell auseinander. Viele setzen auf ad-hoc-Lösungen, die dann bei Änderungen oder Skalierung zusammenbrechen. Das führt zu inkonsistenten Daten, doppelten Events oder fehlenden Triggern.
Ein weiterer Klassiker ist die mangelnde Validierung. Fehlerhafte Variablen, falsche Event-Trigger oder unvollständige Daten im Data Layer führen zu falschen Insights – und das erkennt man meist erst viel zu spät. Deshalb: Nutze Test-Tools und automatisierte Validierungen, um die Datenqualität kontinuierlich sicherzustellen.
Auch die Performance darf nicht vergessen werden: Überladenes JavaScript, unnötige Event-Listener oder unoptimierte Datenübertragungen verlangsamen die Seite und beeinträchtigen das Nutzererlebnis. Das wiederum wirkt sich indirekt auf die Conversion-Rate aus.
Schließlich ist die Wartbarkeit eine Achillesferse: Wenn dein Data Layer nur im Kopf der Entwickler existiert, wird er irgendwann unkontrollierbar. Dokumentation, Versionierung und klare Verantwortlichkeiten sind hier Pflicht. Nur so bleibt dein Tracking langfristig stabil.
Automatisierung und Wartung – damit dein Data Layer nie wieder veraltet
Tracking ist kein einmaliges Projekt, sondern eine kontinuierliche Aufgabe. Automatisiere daher so viel wie möglich: Nutze Skripte, Templates, Versionierung und CI/CD-Prozesse, um Änderungen schnell, fehlerfrei und nachvollziehbar umzusetzen. Mit automatisierten Tests kannst du zudem Regressionen vermeiden und sicherstellen, dass dein Data Layer immer aktuell bleibt.
Ein weiterer Tipp: Dokumentiere alle Events, Variablen und Trigger zentral in einem Tool oder einer Wiki. Das erleichtert die Wartung erheblich, gerade wenn Teams wechseln oder neue Anforderungen entstehen. Regelmäßige Schulungen und Updates im Team sorgen dafür, dass alle auf dem gleichen Stand bleiben.
Langfristig lohnt sich auch die Integration von Monitoring-Tools, die automatisch prüfen, ob die Daten korrekt übertragen werden. Bei Abweichungen oder Fehlern bekommst du frühzeitig Alarm – so kannst du proaktiv gegensteuern, bevor es zu Datenverlust oder falschen Insights kommt.
Die Bedeutung eines konsistenten Data Layer Konzepts für Cross-Channel-Tracking
In einer Welt, in der Nutzer auf verschiedenen Geräten, Kanälen und Plattformen unterwegs sind, ist ein einheitliches Data Layer Konzept unerlässlich. Nur so kannst du eine konsistente Nutzerreise abbilden, Cross-Device-Tracking realisieren und verlässliche Customer Journeys erstellen.
Hierbei ist es wichtig, dass dein Data Layer möglichst plattformunabhängig aufgebaut ist. Das bedeutet: gleiche Variablen, gleiche Events, gleiche Datenstrukturen – egal ob auf Website, App oder in der E-Mail-Kampagne. Nur so kannst du später alle Daten nahtlos zusammenfügen und eine 360-Grad-Sicht auf den Nutzer erhalten.
Das erfordert eine enge Zusammenarbeit zwischen den Teams – Development, Analytics, Marketing. Nur wenn alle an einem Strang ziehen, kannst du ein robustes, skalierbares Data Layer aufbauen, das auch zukünftigen Anforderungen gewachsen ist.
Fazit: Ohne Data Layer Event Konzept – keine Chance im digitalen Zeitalter
Wer heute noch glaubt, schnelles Einbauen einzelner Tracking-Tags reiche aus, der lebt in der Vergangenheit. Das moderne Tracking ist komplex, dynamisch und vor allem: strategisch. Das Data Layer Event Konzept ist die Grundlage für saubere, flexible und skalierbare Datenarchitekturen, die dir echte Insights liefern – und nicht nur Chaos im Code. Es ist der Schlüssel, um Nutzerverhalten präzise zu messen, Conversion-Optimierungen durchzuführen und letztlich im Wettbewerb die Nase vorne zu haben.
Ohne eine klare Strategie, eine saubere technische Umsetzung und kontinuierliche Wartung bist du im Daten-Dschungel verloren. Das Ergebnis: Unzuverlässige Daten, falsche Entscheidungen und am Ende des Tages: verlorene Umsätze. Also, mach Schluss mit dem Chaos – entwickle dein Data Layer Event Konzept jetzt, bevor es zu spät ist. Denn im digitalen Wettbewerb gewinnt, wer seine Daten im Griff hat. Und das ist kein Nice-to-have, sondern das absolute Minimum.