




Data Science Workflow: Clever zum Erfolg navigieren
Du hast von Data Science gehört, aber glaubst immer noch, ein paar bunte Dashboards und ein bisschen Python-Code reichen für den Durchbruch? Willkommen in der Realität: Ohne einen gnadenlos strukturierten, technisch sauberen Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ist dein Projekt in etwa so robust wie ein Sandcastle bei Flut. In diesem Artikel zeigen wir dir den kompletten, ungeschönten Fahrplan – von der Datenhölle bis zum belastbaren Business-Impact. Kein Marketing-Bullshit, sondern eine Schritt-für-Schritt-Anleitung für alle, die Data Science nicht mehr nur spielen, sondern meistern wollen.
- Was ein Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... wirklich ist – und warum er deine Projekte rettet
- Die wichtigsten Phasen im Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz...: Von Datenbeschaffung bis Deployment
- Warum Datenqualität und Feature Engineering alles entscheiden – egal wie smart dein Modell ist
- Welche Tools, Frameworks und Programmiersprachen du 2024 wirklich brauchst
- Wie du mit reproducible Workflows, Versionierung und CI/CD Data Science skalierbar machst
- Warum Collaboration, Dokumentation und Monitoring im WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... keine netten Extras sind, sondern Überlebensgaranten
- Die fünf größten Fehler im Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... – und wie du sie clever vermeidest
- Eine Step-by-Step-Anleitung für einen erfolgreichen Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz..., den du sofort anwenden kannst
- Welche Trends und Technologien du in den nächsten Jahren auf dem Schirm haben musst
Jeder redet über Data Science, aber fast niemand versteht, wie ein Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... in der Praxis zum echten Erfolg führt. Stattdessen wird gebastelt, improvisiert und gehofft – bis das Projekt an schlechter Datenqualität, chaotischer Code-Organisation oder fehlender Skalierbarkeit scheitert. Die Wahrheit ist: Ein sauberer Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ist keine akademische Spielerei, sondern der einzige Weg, wie aus Daten überhaupt verwertbare Erkenntnisse werden. Wer die Phasen, Prinzipien und Tools dieses Workflows nicht kennt, kann sich Machine LearningMachine Learning: Algorithmische Revolution oder Buzzword-Bingo? Machine Learning (auf Deutsch: Maschinelles Lernen) ist der Teilbereich der künstlichen Intelligenz (KI), bei dem Algorithmen und Modelle entwickelt werden, die aus Daten selbstständig lernen und sich verbessern können – ohne dass sie explizit programmiert werden. Klingt nach Science-Fiction, ist aber längst Alltag: Von Spamfiltern über Gesichtserkennung bis zu Produktempfehlungen basiert mehr digitale Realität..., AI und Big DataBig Data: Datenflut, Analyse und die Zukunft digitaler Entscheidungen Big Data bezeichnet nicht einfach nur „viele Daten“. Es ist das Buzzword für eine technologische Revolution, die Unternehmen, Märkte und gesellschaftliche Prozesse bis ins Mark verändert. Gemeint ist die Verarbeitung, Analyse und Nutzung riesiger, komplexer und oft unstrukturierter Datenmengen, die mit klassischen Methoden schlicht nicht mehr zu bändigen sind. Big Data... direkt sparen – und sollte das Budget lieber in guten Kaffee investieren. Wir zeigen dir, wie du 2024 und darüber hinaus clever zum Data-Science-Erfolg navigierst.
Was ist ein Data Science Workflow – und warum ist er der Gamechanger?
Der Begriff Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... klingt nach Prozessdiagrammen und PowerPoint, ist aber in Wirklichkeit das technische Rückgrat jedes ernstzunehmenden Data-Projekts. Ein Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... beschreibt alle Schritte, die notwendig sind, um aus rohen, chaotischen Daten robuste, wiederverwendbare Modelle und belastbare Erkenntnisse zu gewinnen. Klingt abstrakt? Ist es nicht. Ohne einen durchdachten WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... stehst du nach dem dritten Experiment vor einem Datensumpf, nicht wiederholbaren Ergebnissen und Code, den kein Mensch mehr versteht. Willkommen im Data-Sumpf der Marketingabteilungen.
Ein Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... besteht nicht aus ein paar Zeilen Jupyter Notebook, sondern aus einer klaren Abfolge von Phasen: Datenbeschaffung, Datenvorverarbeitung, Explorative Analyse, Feature Engineering, Modellierung, Validierung, Deployment und Monitoring. Diese Abläufe sind keine “nice to have”-Checkliste, sondern der Unterschied zwischen Erfolg und Datenfriedhof. Wer einzelne Phasen überspringt, kompromittiert das gesamte Projekt – und produziert im schlimmsten Fall Modelle, die im Productiveinsatz grandios scheitern.
Und noch wichtiger: Der Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ist nicht linear. Es ist ein iterativer, dynamischer Prozess, in dem du ständig zwischen den Phasen springst, Hypothesen überprüfst, Modelle neu trainierst und Fehlerquellen eliminierst. Wer das als lästige Zeitverschwendung abtut, hat Data Science nicht verstanden – und produziert Ergebnisse, die in der Praxis nie den Härtetest bestehen.
Ein sauberer Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ist die einzige Versicherung gegen die drei größten Feinde jedes Projekts: Daten-Chaos, Experimentier-Wildwuchs und unkontrollierbare Produktions-Deployments. Er sorgt dafür, dass jedes Ergebnis nachvollziehbar, reproduzierbar und skalierbar bleibt – auch dann, wenn das Team wechselt oder die Datenbasis sich radikal ändert.
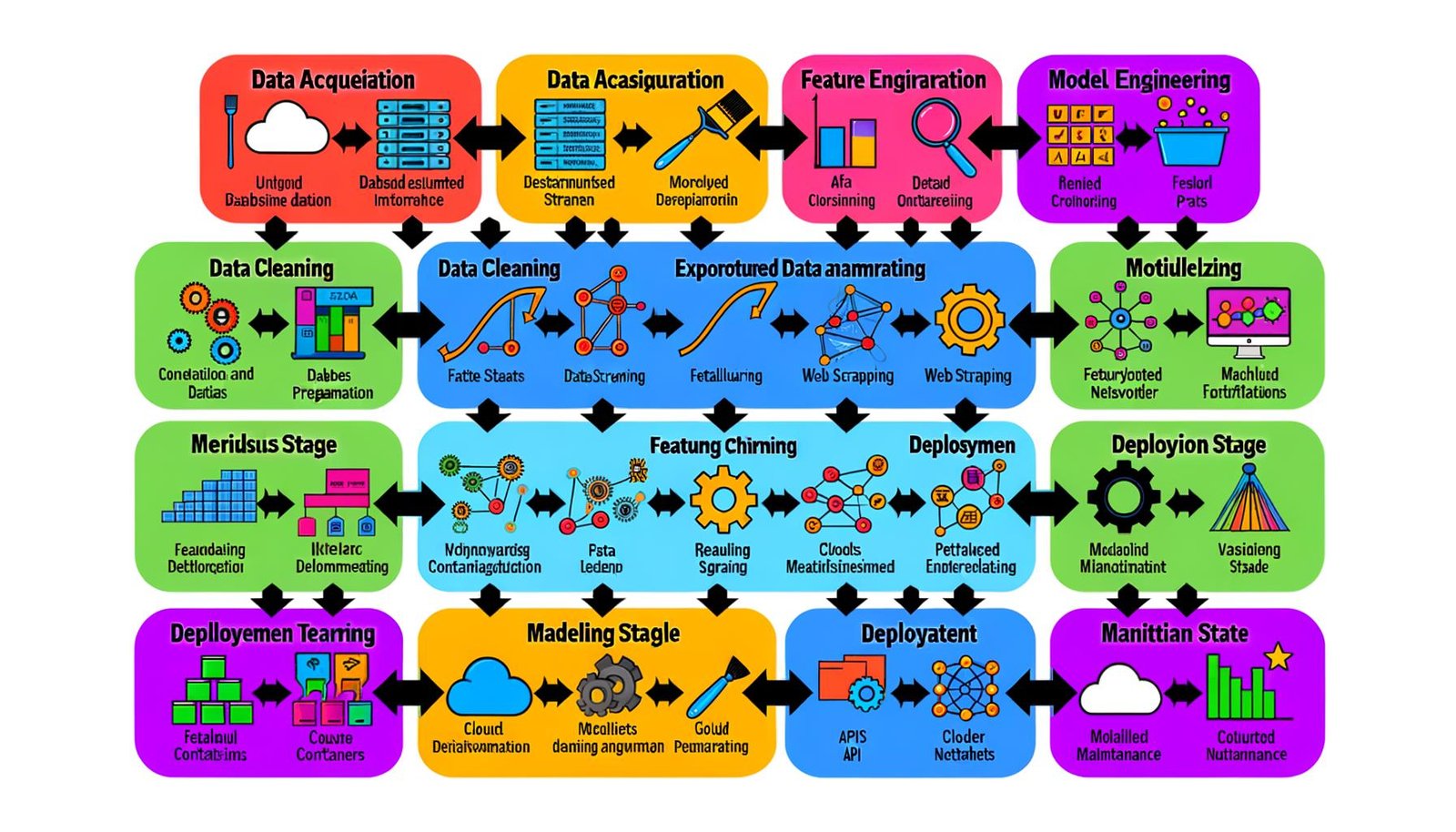
Die Phasen im Data Science Workflow: Von Datenhölle bis Deployment
Jeder Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... besteht aus mehreren, klar definierten Phasen. Jede Phase ist ein potenzieller Stolperstein – und wird regelmäßig von selbsternannten “Data Scientists” unterschätzt. Unser Workflow-Manifest:
- Datenbeschaffung (Data AcquisitionAcquisition: Der Motor hinter Wachstum und Marktanteil im digitalen Marketing Acquisition – das klingt erst mal nach einer steifen PowerPoint-Präsentation im Großraumbüro oder nach dem Lieblingsspielzeug von Unternehmensberatern. Tatsächlich verbirgt sich dahinter einer der entscheidenden Begriffe des Marketings, insbesondere im digitalen Kontext: Es geht um die zielgerichtete Gewinnung von neuen Kunden, Nutzern, Leads oder Transaktionen. Acquisition ist der Startschuss für...): Ohne Daten keine Data Science, so simpel ist das. Hier geht es um die Identifikation, den Zugriff und die Extraktion relevanter Datenquellen. Typische Tools: SQL, APIs, Datenbanken, Web ScrapingScraping: Daten abgreifen wie die Profis – und warum das Netz davor Angst hat Scraping bezeichnet das automatisierte Extrahieren von Daten aus Webseiten oder digitalen Schnittstellen. Wer glaubt, dass das nur was für Hacker im dunklen Hoodie ist, liegt daneben: Scraping ist eine zentrale Technik im digitalen Zeitalter – für SEOs, Marketer, Analysten, Journalisten und sogar für die Konkurrenzbeobachtung. Aber..., ETL-Prozesse. Fehler in dieser Phase ziehen sich wie ein Virus durch das gesamte Projekt.
- Datenvorverarbeitung (Data Cleaning/Preparation): Willkommen im Daten-Dschungel. Hier werden fehlende Werte, Ausreißer, Inkonsistenzen und Formatierungsprobleme bereinigt. Techniken wie Imputation, Normalisierung, Skalierung und Encoding sind Pflicht. Schlechte Datenqualität killt jedes noch so smarte Modell.
- Explorative Datenanalyse (EDA): Wer EDA überspringt, arbeitet blind. Hier werden Datenstrukturen, Verteilungen, Korrelationen und Ausreißer untersucht. Tools: Pandas, Matplotlib, Seaborn, Plotly. Ziel: Hypothesen bilden, Muster erkennen, Problemstellen identifizieren.
- Feature Engineering: Das oft unterschätzte Herzstück. Hier werden aus Rohdaten die wirklich relevanten Merkmale extrahiert, kombiniert und transformiert. Ohne gutes Feature Engineering bleibt jedes Modell ein stumpfes Werkzeug.
- Modellierung (Modeling): Jetzt wird’s spannend: Auswahl, Training und Tuning von Machine LearningMachine Learning: Algorithmische Revolution oder Buzzword-Bingo? Machine Learning (auf Deutsch: Maschinelles Lernen) ist der Teilbereich der künstlichen Intelligenz (KI), bei dem Algorithmen und Modelle entwickelt werden, die aus Daten selbstständig lernen und sich verbessern können – ohne dass sie explizit programmiert werden. Klingt nach Science-Fiction, ist aber längst Alltag: Von Spamfiltern über Gesichtserkennung bis zu Produktempfehlungen basiert mehr digitale Realität... Modellen. Klassische Algorithmen (Random Forest, SVM, XGBoost) oder Deep Learning Frameworks (TensorFlow, PyTorch) – die Auswahl entscheidet über Performance und Interpretierbarkeit.
- Validierung (Evaluation): Kein Modell verlässt das Labor ohne harte Tests. Typische Metriken: Accuracy, Precision, Recall, F1-Score, ROC AUC, Cross-Validation. Fehlerquellen: Overfitting, Data Leakage, falsch konfigurierte Splits.
- Deployment: Das Modell muss raus aus dem Jupyter-Notebook und rein in produktive Systeme. Hier entscheidet sich, ob Data Science echten Business-Impact erzeugt. Typische Tools: Docker, Flask, FastAPI, CI/CD-Pipelines, Cloud-Plattformen.
- Monitoring & Maintenance: Nach dem Deployment ist vor dem Monitoring. Modelle müssen kontinuierlich überwacht, gewartet und regelmäßig neu trainiert werden. Sonst drohen Model Decay, Drift und der sichere Tod jeder Vorhersagegenauigkeit.
Jede Phase hat ihre eigenen technischen Herausforderungen, Stolperfallen und Best Practices. Der Unterschied zwischen Hobby-Data-Science und belastbaren Business-Anwendungen liegt genau in der Gründlichkeit und Systematik, mit der diese Phasen umgesetzt werden.
Und das Wichtigste: Jeder WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ist nur so stark wie sein schwächstes Glied. Wer bei der Datenbereinigung schlampt oder beim Deployment improvisiert, sabotiert sämtliche Investitionen in Modellierung und Optimierung. Die bittere Wahrheit: 80 % der Data Science Projekte scheitern nicht am AlgorithmusAlgorithmus: Das unsichtbare Rückgrat der digitalen Welt Algorithmus – das Wort klingt nach Science-Fiction, ist aber längst Alltag. Ohne Algorithmen läuft heute nichts mehr: Sie steuern Suchmaschinen, Social Media, Navigation, Börsenhandel, Werbung, Maschinen und sogar das, was du in deinem Lieblingsshop zu sehen bekommst. Doch was ist ein Algorithmus eigentlich, wie funktioniert er und warum ist er das ultimative Werkzeug..., sondern am Workflow-Chaos.
Tools, Frameworks und Technologien: Was du wirklich brauchst
Die Tool-Landschaft im Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ist ein Dschungel. Jeder will den neuen heißen Scheiß, aber kaum jemand versteht, welche Tools wirklich einen Unterschied machen. Hier die Basics, ohne die du 2024 nicht arbeiten solltest – plus ein paar disruptive Technologien, die du kennen musst, wenn du nicht wie der letzte Excel-Jongleur wirken willst.
Programmiersprachen: Python oder R? Die Antwort ist einfach: Python dominiert, weil es alle relevanten Libraries und Frameworks integriert. R ist noch im akademischen Bereich verbreitet, aber in der Industrie fast tot. Wer heute Data Science macht, setzt auf Pandas, NumPy, Scikit-Learn, TensorFlow oder PyTorch – alles Python-first.
Datenmanagement und Verarbeitung: SQL bleibt Pflicht, weil 80 % der Daten in relationalen Systemen liegen. Für Big DataBig Data: Datenflut, Analyse und die Zukunft digitaler Entscheidungen Big Data bezeichnet nicht einfach nur „viele Daten“. Es ist das Buzzword für eine technologische Revolution, die Unternehmen, Märkte und gesellschaftliche Prozesse bis ins Mark verändert. Gemeint ist die Verarbeitung, Analyse und Nutzung riesiger, komplexer und oft unstrukturierter Datenmengen, die mit klassischen Methoden schlicht nicht mehr zu bändigen sind. Big Data...: Apache Spark, Hadoop oder Databricks. Für ETL-Prozesse: Airflow, Luigi, Prefect. Wer Daten nicht effizient extrahieren, transformieren und laden kann, ist im WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... abgehängt.
Versionierung und Reproducibility: Git ist Standard, aber für Data Science reicht das nicht. Tools wie DVC (Data Version Control), MLflow oder Weights & Biases sorgen dafür, dass nicht nur Code, sondern auch Daten, Modelle und Experimente versioniert werden. Ohne das ist jeder WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... eine Blackbox.
Deployment und Skalierung: Containerisierung mit Docker, Orchestrierung via Kubernetes, CI/CD-Pipelines mit GitHub Actions oder GitLab CI sind heute Pflicht. Für den produktiven Rollout: FastAPI, Flask, TensorFlow Serving, Seldon Core, AWS SageMaker oder Azure ML. Alles andere ist Bastelbude.
Datenvisualisierung und EDA: Matplotlib, Seaborn, Plotly, Dash, Streamlit – je nach Use Case. Wer seine Ergebnisse nicht verständlich visualisieren kann, verliert sofort die Stakeholder.
Unterm Strich: Die Tool-Auswahl muss zum WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... passen – nicht umgekehrt. Wer zu viel Zeit mit Tool-Hopping und Framework-Bashing verbringt, verliert den Fokus auf das, was wirklich zählt: Data Science, die echten Mehrwert schafft.
Reproducible Workflows, Collaboration und Monitoring – der Unterschied zwischen Chaos und Skalierung
Data Science ist längst kein Solo-Game mehr. Wer im Team arbeitet (und das ist in jedem ernsthaften Unternehmen der Regelfall), muss kollaborative, reproduzierbare Workflows etablieren. Sonst endet jedes Projekt nach ein paar Monaten im “Sorry, das kann ich nicht mehr nachbauen”-Fiasko.
Reproduzierbarkeit ist das Herzstück jedes professionellen Data Science Workflows. Gemeint ist: Jeder Schritt, jede Transformation, jedes Modell muss exakt wiederholbar sein – egal, wer im Team daran arbeitet. Das erreichst du nur mit konsequenter Versionierung von Code, Daten und Modellen (siehe DVC, MLflow), sauber dokumentierten Pipelines und klar definierten Umgebungen (Conda, Docker-Images).
Collaboration lebt von strukturierter Code-Organisation, sauberem Code-Review und nachvollziehbaren Experiment-Logs. Wer im Notebook-Wildwuchs arbeitet oder Ergebnisse in Slack-Nachrichten teilt, produziert keine Wissenschaft, sondern Chaos. Moderne Teams nutzen zentrale Repositories, automatisierte Tests und strukturierte Projekt-Boards (Jira, GitHub Projects).
Monitoring ist der dritte, oft unterschätzte Pfeiler. Nach dem Deployment beginnt die eigentliche Arbeit: Modell-Performance überwachen, Daten-Drift erkennen, Fehlerquellen identifizieren und Modelle rechtzeitig retrainieren. Tools wie Prometheus, Grafana, Seldon Core oder MLflow TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... liefern die nötige Infrastruktur für echtes MLOps – nicht nur für “Proof of Concepts”, sondern für echte Business-Anwendungen.
Das Ziel: Ein WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz..., der jederzeit nachvollziehbar, reproduzierbar und skalierbar ist. Wer das ignoriert, produziert zwar viele Experimente, aber keinen nachhaltigen, produktiven Mehrwert.
Die fünf größten Fehler im Data Science Workflow – und wie du sie clever vermeidest
Obwohl Data Science längst als Königsdisziplin gefeiert wird, scheitern 80 % der Projekte an denselben Fehlern. Hier die Top Five – und wie du sie umgehst, bevor sie dich ruinieren:
- Datenqualität unterschätzen: Schlechte Daten lassen sich nicht durch fancy Modelle retten. Investiere 60 % der Zeit ins Data Cleaning, nicht ins Hyperparameter-Tuning.
- Feature Engineering vernachlässigen: Mehr Features ≠ bessere Modelle. Aber schlechte Features ruinieren alles. Setze auf Domain-Wissen, nicht nur auf Automatismen.
- Keine Reproducibility: Wer seine Schritte nicht dokumentiert und versioniert, kann keine Fehler finden – und muss jedes Experiment doppelt machen.
- Deployment auf die lange Bank schieben: Modelle, die nie produktiv gehen, sind teuer bezahlte Prototypen. Plane die Produktivsetzung von Anfang an mit, nicht erst, wenn das Notebook “fertig” ist.
- Monitoring vergessen: Modelle verschlechtern sich – immer. Ohne Überwachung und Retraining wird aus jedem AI-System spätestens nach sechs Monaten ein Zombie.
Die Lösung: Stringenter WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz..., kompromisslose Datenhygiene und ein Team, das für kontinuierliche Verbesserungen brennt – nicht für kurzfristige “Proof of Concept”-Egos.
Step-by-Step: So baust du einen Data Science Workflow, der wirklich funktioniert
Es gibt keine magische Abkürzung, aber ein bewährtes Framework, das in jedem ernsthaften Data Science Projekt funktioniert. Hier der Ablauf – von der Datenhölle bis zum Business-Impact:
- Datenquellen identifizieren und extrahieren: Definiere relevante interne und externe Datenquellen. Extrahiere Daten via SQL, APIs oder ETL-Prozesse. Dokumentiere jede Datenquelle inklusive Zugriff, Schema und Aktualisierungsfrequenz.
- Datenbereinigung und Transformation: Analysiere fehlende Werte, Inkonsistenzen und Ausreißer. Implementiere Data Cleaning, Normalisierung, Skalierung und Encoding. Lege einen Datenqualitätsbericht an.
- Explorative Datenanalyse (EDA): Visualisiere Verteilungen, Korrelationen und Ausreißer. Identifiziere Muster und Hypothesen. Teile EDA-Berichte mit dem Team.
- Feature Engineering: Entwickle neue Features, transformiere bestehende, eliminiere irrelevante Merkmale. Dokumentiere jede Änderung, damit sie nachvollziehbar bleibt.
- Modellauswahl und Training: Vergleiche verschiedene Algorithmen, tune Hyperparameter, führe Cross-Validation durch. Versioniere alle Experimente mit Tools wie MLflow oder DVC.
- Modellvalidierung: Evaluiere die Modelle mit klaren Metriken. Überprüfe auf Overfitting und Data Leakage. Erstelle einen Validierungsreport.
- Deployment vorbereiten: Verpacke das Modell in einem Docker-Container oder als APIAPI – Schnittstellen, Macht und Missverständnisse im Web API steht für „Application Programming Interface“, zu Deutsch: Programmierschnittstelle. Eine API ist das unsichtbare Rückgrat moderner Softwareentwicklung und Online-Marketing-Technologien. Sie ermöglicht es verschiedenen Programmen, Systemen oder Diensten, miteinander zu kommunizieren – und zwar kontrolliert, standardisiert und (im Idealfall) sicher. APIs sind das, was das Web zusammenhält, auch wenn kein Nutzer je eine... (Flask, FastAPI). Richte CI/CD-Pipelines für automatisierte Deployments ein.
- Monitoring implementieren: Überwache Modell-Performance, Daten-Drift und System-Health mit geeigneten Monitoring-Tools. Setze Alerts für kritische Schwellenwerte.
- Dokumentation und Kommunikation: Halte alle Schritte, Entscheidungen und Ergebnisse transparent und nachvollziehbar fest. Teile Reports regelmäßig mit Stakeholdern.
- Kontinuierliche Verbesserung: Plane regelmäßige Retrainings, Updates und Evaluierungen ein. Optimiere den WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... fortlaufend.
Jeder dieser Schritte ist keine Option, sondern Pflicht. Wer Workflow-Lücken ignoriert, zahlt später mit massiven Problemen – von Datenchaos bis zu gescheiterten Deployments.
Data Science Workflow: Trends und Technologien, die du nicht verschlafen darfst
Stillstand ist Rückschritt – nirgendwo mehr als im Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz.... Wer 2024 und darüber hinaus relevant bleiben will, muss die wichtigsten Trends auf dem Radar haben:
- MLOps: Die Integration von Machine LearningMachine Learning: Algorithmische Revolution oder Buzzword-Bingo? Machine Learning (auf Deutsch: Maschinelles Lernen) ist der Teilbereich der künstlichen Intelligenz (KI), bei dem Algorithmen und Modelle entwickelt werden, die aus Daten selbstständig lernen und sich verbessern können – ohne dass sie explizit programmiert werden. Klingt nach Science-Fiction, ist aber längst Alltag: Von Spamfiltern über Gesichtserkennung bis zu Produktempfehlungen basiert mehr digitale Realität... in DevOps-Prozesse wird zum Industriestandard. Automatisiertes Deployment, Monitoring und Retraining sind keine Kür mehr, sondern Pflicht.
- Automated Machine LearningMachine Learning: Algorithmische Revolution oder Buzzword-Bingo? Machine Learning (auf Deutsch: Maschinelles Lernen) ist der Teilbereich der künstlichen Intelligenz (KI), bei dem Algorithmen und Modelle entwickelt werden, die aus Daten selbstständig lernen und sich verbessern können – ohne dass sie explizit programmiert werden. Klingt nach Science-Fiction, ist aber längst Alltag: Von Spamfiltern über Gesichtserkennung bis zu Produktempfehlungen basiert mehr digitale Realität... (AutoML): Tools wie DataRobot, H2O.ai oder Azure AutoML nehmen viele Modellierungsschritte ab – aber nur, wenn die Datenbasis stimmt und die Prozesse sauber integriert sind.
- Data Lineage und Governance: Wer nicht nachvollziehen kann, woher seine Daten stammen, verliert im Compliance- und Qualitätswettlauf. Lösungen wie Great Expectations oder OpenLineage werden zum Standard.
- Feature Stores: Zentrale Repositories wie Feast oder Tecton ermöglichen das Teilen und Wiederverwenden von Features – ein Muss für skalierbare Modelle im Unternehmen.
- Edge AI & Federated Learning: Modelle wandern auf Endgeräte und werden dezentral trainiert. Der WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... muss darauf vorbereitet sein – von Daten-Handling bis Deployment.
Die Message ist klar: Workflow-Technologie entscheidet über Geschwindigkeit, Skalierung und Resilienz. Wer hier nicht up-to-date bleibt, wird schnell digital abgehängt.
Fazit: Ohne sauberen Data Science Workflow bleibt alles nur Spielerei
Data Science ist kein Zaubertrick, kein Dashboard-Bingo und schon gar kein Marketing-Gag. Der Unterschied zwischen Spielerei und echtem Business-Impact liegt im Data Science WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... – kompromisslos, strukturiert und technisch sauber. Wer die Phasen, Tools und Prinzipien dieses Workflows nicht durchdringt, wird im Daten-Nebel untergehen, egal wie viele Python-Zertifikate an der Wand hängen.
Die bittere Wahrheit: Es gibt keinen Shortcut. Nur wer Daten, Prozesse und Modelle radikal systematisiert, schafft Wert, der hält. Der Rest kann weiter im Notebook experimentieren – oder endlich anfangen, Data Science als echten WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... zu leben. Willkommen bei 404 – wo Daten nicht nur gesammelt, sondern clever zum Erfolg navigiert werden.



