




Data Engineering Workflow: Effizient, Clever, Unverzichtbar
Wer glaubt, Daten fließen von allein ins Data Warehouse und werden dort auf magische Weise zu wertvollen Business-Insights fermentiert, lebt im Märchenland der Data-Naiven. Willkommen in der brutalen Realität: Ohne einen harten, ausgeklügelten Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... bleibt dein Datenschatz ein Haufen wertloser Rohdaten – egal wie viele “Data Scientists” du auf ihn hetzt. In diesem Guide zerlegen wir den Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... bis auf den letzten Byte, zeigen dir, warum Effizienz und Cleverness hier keine Kür, sondern absolute Pflicht sind – und warum Unternehmen ohne sauberen WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... gnadenlos untergehen.
- Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz...: Definition, Bedeutung und warum ohne ihn nichts läuft
- Die wichtigsten Bestandteile eines effizienten Data Engineering Workflows – von Datenquellen bis Deployment
- Schlüsseltechnologien: ETL, ELT, Data Pipelines, Orchestrierung und Automatisierung
- Wichtige Tools im Data Engineering (Airflow, dbt, Kafka, Spark, Fivetran, Snowflake & Co.)
- Best Practices für Skalierbarkeit, Wartung und Fehlerresilienz im WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz...
- Datenqualität und Monitoring: Warum schlechte Daten teurer sind als kein Data Engineering
- Step-by-Step: Wie du einen robusten Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... aufbaust
- Typische Fehler, die dich Millionen kosten – und wie du sie vermeidest
- Fazit: Warum Data Engineering Workflows das Rückgrat jeder datengetriebenen Organisation sind
Wer 2025 noch glaubt, Data Engineering sei ein hübscher Nebenjob für Tech-Nerds, der hat die digitale Evolution verschlafen. Der Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ist das unsichtbare Rückgrat jeder modernen Organisation. Ohne ihn ist alles Daten-Storytelling heiße Luft, Machine LearningMachine Learning: Algorithmische Revolution oder Buzzword-Bingo? Machine Learning (auf Deutsch: Maschinelles Lernen) ist der Teilbereich der künstlichen Intelligenz (KI), bei dem Algorithmen und Modelle entwickelt werden, die aus Daten selbstständig lernen und sich verbessern können – ohne dass sie explizit programmiert werden. Klingt nach Science-Fiction, ist aber längst Alltag: Von Spamfiltern über Gesichtserkennung bis zu Produktempfehlungen basiert mehr digitale Realität... ein Rohrkrepierer und Business Intelligence bestenfalls Kaffeesatzleserei. Dieser Artikel ist dein technischer Deep Dive in die Mechanik, die hinter jeder erfolgreichen Data-Initiative steht – und der Grund, warum Unternehmen ohne sauberen WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... schon morgen von der Konkurrenz überholt werden. Es wird technisch, es wird schonungslos – und du wirst nie wieder “Data Engineering” in einem Meeting unterschätzen.
Data Engineering Workflow: Definition, Bedeutung und warum ohne ihn nichts läuft
Der Begriff “Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz...” ist kein Buzzword aus einer hippen Consulting-Präsentation, sondern die knallharte Realität hinter jedem datengetriebenen Unternehmen. Er umfasst sämtliche Prozesse, Werkzeuge und Strukturen, mit denen Rohdaten von der Erzeugung bis zur finalen Analyse transportiert, transformiert, geprüft und bereitgestellt werden. Ein Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ist alles – außer optional.
Warum ist der Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... so verdammt wichtig? Ganz einfach: Weil Daten erst dann wertvoll sind, wenn sie zugänglich, vertrauenswürdig, strukturiert und aktuell vorliegen. Jeder Schritt in diesem WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... – ob Extraction, Transformation, Loading (ETL), Data Quality Checks, Orchestrierung oder Monitoring – entscheidet über Erfolg oder Scheitern deiner gesamten Data-Strategie. Wer beim Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... schlampig arbeitet, produziert teuer bezahlten Datenmüll und zerstört jede Hoffnung auf sinnvolle Analysen.
In der Praxis bedeutet das: Ohne einen durchdachten Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... endest du im Datenchaos. Daten liegen in Silos, Analysen dauern Wochen, jede neue Datenquelle wird zum Mammutprojekt, und “Datenkompetenz” bleibt ein leeres Versprechen. Die Konsequenz? Schlechte Entscheidungen, Frust im Team und ein CEO, der beim nächsten Budget-Meeting die Data-Abteilung zum Abschuss freigibt.
Die wichtigsten Eigenschaften eines erfolgreichen Workflows sind Effizienz, Skalierbarkeit, Automatisierung und Fehlerresilienz. Wer diese Prinzipien nicht beherrscht, wird von der Datenflut überrollt und zahlt doppelt: zuerst mit explodierenden Engineering-Kosten, dann mit massiven Wettbewerbsnachteilen. Willkommen im Darwinismus der Datenökonomie.
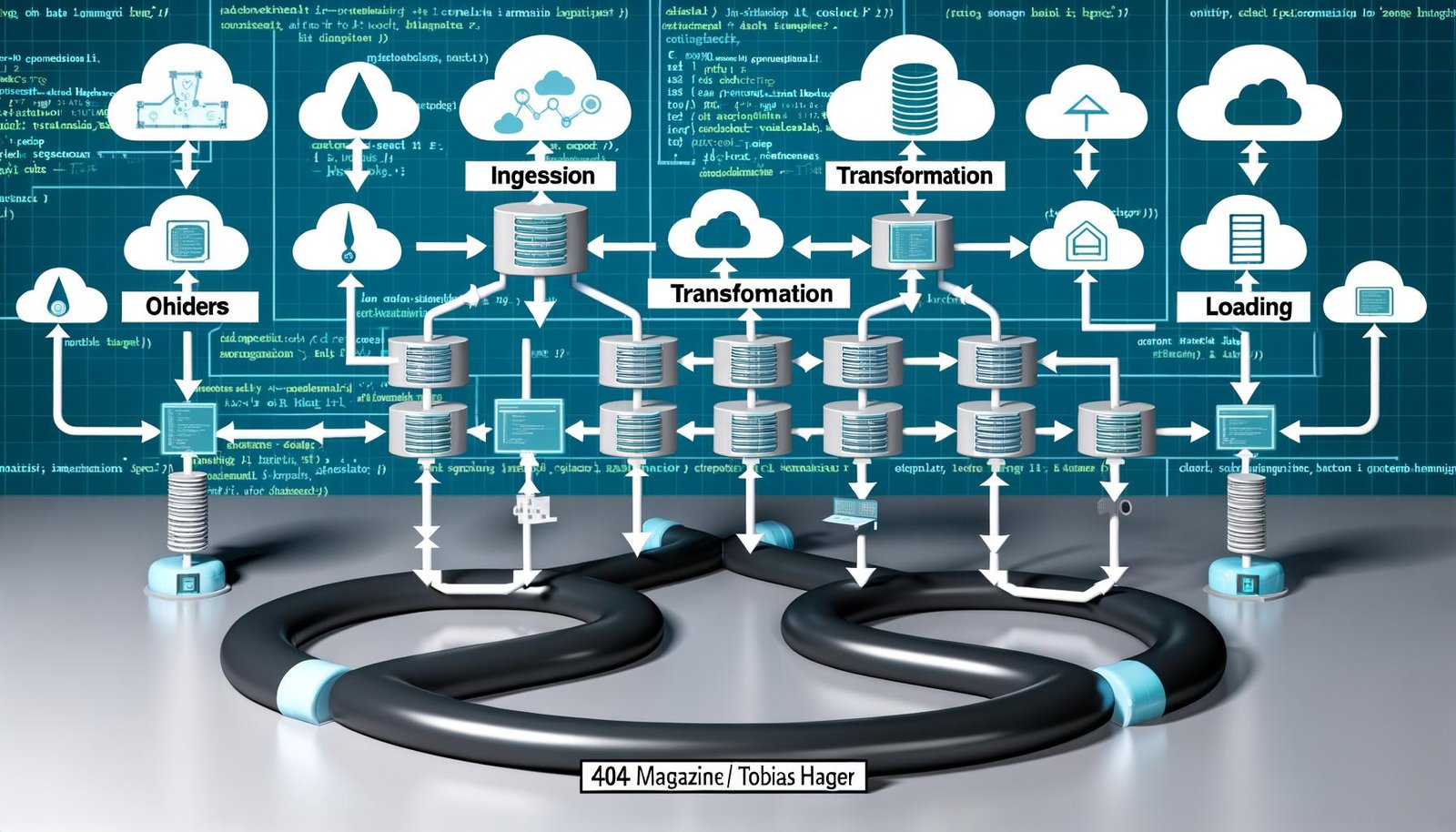
Die Bestandteile eines effizienten Data Engineering Workflows: Von der Quelle bis zum Deployment
Ein Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz..., der den Namen verdient, besteht aus mehreren klar definierten Phasen. Jede davon ist ein potenzieller Single Point of Failure – und jede muss technisch sauber gelöst werden. Wer hier mit halbgaren Bastellösungen arbeitet, spielt russisches Roulette mit seiner Datenstrategie.
Die fünf essenziellen Bestandteile eines Data Engineering Workflows sind:
- Datenquellen (Sources): Relationale Datenbanken, APIs, Flat Files, Event Streams. Jede Quelle hat eigene Eigenheiten, Formate und Herausforderungen – Stichwort: inkonsistente Schemas, fehlende Typisierung, exotische Protokolle.
- Ingestion: Der Prozess, mit dem Rohdaten eingesammelt und ins System gebracht werden. Hier entscheidet sich, wie stabil und performant deine nachgelagerte Pipeline funktioniert. Technologien wie Apache Kafka, Fivetran oder klassische ETL-Tools sind hier im Einsatz.
- Transformation: Rohdaten werden bereinigt, normalisiert, angereichert und in ein einheitliches Zielschema überführt. Ohne saubere Transformation kein konsistenter Datenbestand – und ohne konsistente Daten keine Analyse, die ihren Namen verdient.
- Loading: Die Übertragung der transformierten Daten in das Zielsystem – meist ein Data Warehouse (Snowflake, BigQuery, Redshift) oder ein Data Lake (S3, Azure Data Lake). Hier geht es um Geschwindigkeit, Integrität und Skalierbarkeit.
- Orchestrierung und Monitoring: Die Steuerung und Überwachung aller Prozesse. Ohne Monitoring keine Fehlererkennung, ohne Orchestrierung keine Automatisierung. Airflow, Dagster und Prefect sind die Werkzeuge der Wahl.
Jeder dieser Schritte ist technisch komplex. Failst du bei einem, failst du überall. Deshalb: Kein Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ohne rigorose Planung, Modularisierung und lückenlose Kontrolle.
Was viele unterschätzen: Der Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ist kein Einweg-Prozess, sondern ein Kreislauf. Sobald neue Datenquellen, Transformationsregeln oder Business-Anforderungen ins Spiel kommen, muss der WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... flexibel und erweiterbar bleiben. Ein statisches, monolithisches Setup ist in der Praxis ein Todesurteil.
Schlüsseltechnologien und Tools: So werden Data Engineering Workflows clever und skalierbar
Wer beim Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... über die alten Excel-Importe oder manuelle ETL-Prozesse hinauskommen will, braucht die richtigen Werkzeuge – und zwar von Anfang an. Die Wahl der Technologien entscheidet über Effizienz, Skalierbarkeit und Fehleranfälligkeit deiner gesamten Datenarchitektur. Hier trennt sich die Spreu vom Weizen.
Die wichtigsten Technologie-Konzepte im Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... sind:
- ETL/ELT: Die klassische ETL-Pipeline (Extract-Transform-Load) wird heute oft von ELT (Extract-Load-Transform) abgelöst. Warum? Weil moderne Data Warehouses wie Snowflake oder BigQuery transformationsstark sind und die Transformation ins Zielsystem verlagert werden kann – das steigert Flexibilität und Geschwindigkeit.
- Data Pipelines: Modularisierte, wiederverwendbare Verarbeitungsketten. Hier kommen Frameworks wie Apache Beam, Spark oder dbt ins Spiel. dbt etwa ist das Tool schlechthin für Transformationen im Data Warehouse – und setzt neue Maßstäbe bei Versionierung, Testing und Dokumentation.
- Orchestrierung: Komplexe Workflows brauchen eine zentrale Steuerung. Apache Airflow ist hier Standard, aber auch Prefect und Dagster gewinnen an Boden. Sie ermöglichen das Scheduling, Monitoring und Error-Handling von Pipelines – inklusive Visualisierung und Alerting.
- Streaming: Echtzeitdaten sind längst Pflicht. Kafka, Pulsar oder Kinesis sind die Schwergewichte für Event-getriebene Architekturen und Continuous Data Ingestion.
- Monitoring & Logging: Ohne Monitoring keine verlässliche Pipeline. Prometheus, Grafana, ELK-Stack und spezialisierte Data Observability-Plattformen wie Monte Carlo oder Databand sind hier Pflicht, nicht Kür.
Step-by-step – so sieht ein typischer Stack für einen modernen Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... aus:
- Fivetran oder Airbyte für die automatisierte Datenextraktion
- Apache Kafka für Event Streams und Near-Real-Time-Processing
- Apache Airflow zur Orchestrierung und Steuerung
- dbt für Transformation, Testing und Data Lineage
- Snowflake, BigQuery oder Redshift als skalierbares Data Warehouse
- Prometheus, Grafana & ELK für Monitoring, Logging und Alerting
Wer an Tools spart, spart am falschen Ende. Die richtige Kombination aus bewährten und innovativen Lösungen trennt die Data Engineering Champions von den Data-Dilettanten.
Datenqualität und Monitoring: Warum schlechte Daten teurer sind als kein Data Engineering
Es gibt eine bittere Wahrheit: Datenqualität ist der stille Killer aller Data-Projekte. Ein effizienter Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... schützt dich aber nur dann vor diesem Killer, wenn du Monitoring und Qualitätssicherung von Anfang an integrierst. Wer hier schlampig arbeitet, zahlt doppelt – und zwar jedes Mal, wenn ein Analyst mit fehlerhaften Daten ein wichtiges Reporting baut.
Data Quality Checks sind kein nice-to-have. Sie sind zwingend. Typische Prüfungen umfassen:
- Schema Validation (passt das Datenformat?)
- Null-Checks (fehlen Werte?)
- Range-Checks (liegen Werte im erwarteten Bereich?)
- Uniqueness-Checks (gibt es Dubletten?)
- Referentielle Integrität (sind Relationen gültig?)
Tools wie Great Expectations, dbt Tests oder Soda SQL automatisieren diese Prüfungen und machen sie zum festen Bestandteil jeder Pipeline. Monitoring-Lösungen wie Monte Carlo, Databand oder eigens gebaute Prometheus/Grafana-Setups überwachen nicht nur technische Metriken (Laufzeiten, Fehlerquoten), sondern auch Datenanomalien – und alarmieren proaktiv, bevor der Schaden groß wird.
Wer denkt, Monitoring sei ein einmaliges Setup, hat den Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... nicht verstanden. Datenquellen ändern sich, Upstream-Systeme liefern plötzlich Müll, oder eine Transformation läuft aus dem Ruder. Ohne kontinuierliche Überwachung endet jeder noch so schicke WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... im Debakel – und der CTO steht mit heruntergelassenen Hosen vor dem Aufsichtsrat.
Step-by-Step: So baust du einen robusten Data Engineering Workflow auf
Der Aufbau eines effizienten Data Engineering Workflows ist kein “Quick Win”, sondern ein strukturiertes, technisches Großprojekt. Wer glaubt, ein paar Cronjobs und SQL-Skripte reichen aus, wird schon beim ersten Daten-Desaster eines Besseren belehrt. Damit du nicht in jede Falle tappst, hier die Step-by-Step-Anleitung für den Aufbau eines Workflows, der auch morgen noch funktioniert:
- 1. Anforderungsanalyse & Datenquellen identifizieren:
- Welche Daten werden benötigt? Wo liegen sie? Welche Formate?
- Werden Echtzeit- oder Batch-Daten gebraucht?
- 2. Passende Tools & Technologien auswählen:
- Wähle Ingestion-Tools, Transformations-Frameworks, Data Warehouse/Lake und Orchestrierung passend zur Skalierung und Komplexität.
- 3. Pipeline-Design & Modularisierung:
- Baue einzelne, klar abgegrenzte Pipeline-Module (Ingestion, Transformation, Loading).
- Definiere Schnittstellen und Verträge zwischen den Modulen (APIs, Schemas).
- 4. Automatisierung & Orchestrierung aufsetzen:
- Integriere Scheduling, Monitoring und Alerting mit Tools wie Airflow oder Prefect.
- 5. Data Quality Checks & Monitoring integrieren:
- Automatisiere Schema- und Werteprüfungen, implementiere Alerting bei Fehlern und Anomalien.
- 6. Dokumentation & Data Lineage:
- Stelle sicher, dass jede Transformation nachvollziehbar ist (dbt Docs, Data Catalogs).
- 7. Testing & Deployment:
- Baue Unit- und Integrationstests für Pipelines, implementiere CI/CD für Infrastruktur und Code.
- 8. Betrieb & kontinuierliche Verbesserung:
- Überwache Performance, Fehler und Datenlatenzen, passe den WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... laufend an neue Anforderungen an.
Jeder Schritt ist Pflicht, kein Schritt ist optional. Wer abkürzt, wird von der Realität eingeholt – und zwar schneller, als ihm lieb ist.
Typische Fehler im Data Engineering Workflow – und wie du sie vermeidest
Data Engineering klingt für viele nach Raketenwissenschaft, ist aber in Wahrheit vor allem eins: ein Minenfeld für Anfängerfehler. Die folgenden Fehler sind die Klassiker – und jede Organisation, die sie macht, zahlt am Ende viel Geld für wenig Erkenntnis.
- Silo-Denken: Daten werden von Teams oder Abteilungen isoliert verarbeitet. Ergebnis: redundante Pipelines, inkonsistente Daten, explodierende Kosten.
- Fehlende Automatisierung: Manuelle Eingriffe, Cronjobs, Skript-Chaos. Jede manuelle Aufgabe ist eine Fehlerquelle – und kostet Skalierung.
- Kein Monitoring: Fehler werden erst bemerkt, wenn der Schaden schon da ist. Ein WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ohne Monitoring ist wie Autofahren ohne Armaturenbrett.
- Schlechte Dokumentation: Niemand weiß, wie die Pipelines funktionieren. Bei Personalwechsel droht der komplette Wissensverlust.
- Over-Engineering: Zu viel Komplexität, zu viele Tools, zu viele Abhängigkeiten. Der WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... wird unwartbar und bricht beim ersten Change zusammen.
Die Lösung: Klare Architektur, Automatisierung, Monitoring, Dokumentation und ein Minimalismus, der Skalierbarkeit ermöglicht. Wer das beherzigt, überlebt den Data Engineering Darwinismus – alle anderen sind Datenfutter.
Fazit: Data Engineering Workflow als Wettbewerbsfaktor
Der Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... ist kein nettes Add-on, sondern das Fundament jeder datengetriebenen Organisation. Wer ihn effizient, clever und unverzichtbar gestaltet, schafft die Basis für erfolgreiche Analysen, KI-Projekte und datenbasierte Geschäftsmodelle. Wer ihn vernachlässigt, produziert Datenfriedhöfe und finanziert die Konkurrenz – mit seiner eigenen Inkompetenz.
In einer digitalen Welt, in der Datenvolumen, -geschwindigkeit und -vielfalt explodieren, entscheidet der Data Engineering WorkflowWorkflow: Effizienz, Automatisierung und das Ende der Zettelwirtschaft Ein Workflow ist mehr als nur ein schickes Buzzword für Prozess-Junkies und Management-Gurus. Er ist das strukturelle Skelett, das jeden wiederholbaren Arbeitsablauf in Firmen, Agenturen und sogar in Ein-Mann-Betrieben zusammenhält. Im digitalen Zeitalter bedeutet Workflow: systematisierte, teils automatisierte Abfolge von Aufgaben, Zuständigkeiten, Tools und Daten – mit dem einen Ziel: maximale Effizienz... über Sieg oder Niederlage. Mit den richtigen Prozessen, Tools und einer Prise technischer Demut wird aus Daten ein echter Wettbewerbsvorteil. Alles andere ist Kosmetik – und spätestens beim nächsten Audit gnadenlos entlarvt. Willkommen in der Realität. Willkommen bei 404.



