
GA4 Datendurchfluss verstehen: Datenströme optimal nutzen
Wer heute im Online-Marketing auf den falschen Datenstrom setzt, wird im nächsten Jahr nicht nur abgehängt – er wird digital zerdrückt. Google AnalyticsGoogle Analytics: Das absolute Must-have-Tool für datengetriebene Online-Marketer Google Analytics ist das weltweit meistgenutzte Webanalyse-Tool und gilt als Standard, wenn es darum geht, das Verhalten von Website-Besuchern präzise und in Echtzeit zu messen. Es ermöglicht die Sammlung, Auswertung und Visualisierung von Nutzerdaten – von simplen Seitenaufrufen bis hin zu ausgefeilten Conversion-Funnels. Wer seine Website im Blindflug betreibt, ist selbst schuld:... 4 ist kein Werkzeug mehr, um hübsche Reports zu erstellen; es ist die zentrale Schaltstelle für dein gesamtes Daten-Ökosystem. Doch nur wer den komplexen Datenfluss hinter den Kulissen durchschaut, kann die volle Power von GA4 entfesseln. Ansonsten sitzt du im Dunkeln, während deine Konkurrenz mit klaren Insights abkassiert.
- Was ist der GA4-Datendurchfluss und warum ist er so wichtig?
- Die Architektur von GA4: Datenströme, Events und User Journeys
- Wie Daten in GA4 fließen: Von der User-Interaktion bis zum Bericht
- Optimale Nutzung der Datenströme: Konfiguration, Debugging und Automatisierung
- Herausforderungen im Data-Flow: DatenschutzDatenschutz: Die unterschätzte Macht über digitale Identitäten und Datenflüsse Datenschutz ist der Begriff, der im digitalen Zeitalter ständig beschworen, aber selten wirklich verstanden wird. Gemeint ist der Schutz personenbezogener Daten vor Missbrauch, Überwachung, Diebstahl und Manipulation – egal ob sie in der Cloud, auf Servern oder auf deinem Smartphone herumlungern. Datenschutz ist nicht bloß ein juristisches Feigenblatt für Unternehmen, sondern..., Filter und Datenqualität
- Tools und Techniken zur Analyse des GA4-Datendurchflusses
- Best Practices: Datenströme für maximale Insights und ROIROI (Return on Investment): Die härteste Währung im Online-Marketing ROI steht für Return on Investment – also die Rendite, die du auf einen eingesetzten Betrag erzielst. In der Marketing- und Business-Welt ist der ROI der unbestechliche Gradmesser für Erfolg, Effizienz und Wirtschaftlichkeit. Keine Ausrede, kein Blabla: Wer den ROI nicht kennt, spielt blind. In diesem Glossar-Artikel bekommst du einen schonungslos...
- Fehlerquellen und Fallstricke: Was deine Daten verfälschen kann
- Zukunftsausblick: Datenarchitekturen 2025 und darüber hinaus
In einer Welt, in der Daten die neue Währung sind, ist das Verständnis des eigenen GA4-Datendurchflusses der Schlüssel zum Erfolg. Wer nur oberflächlich auf Reports schaut, verpasst das große Ganze – nämlich, wie die eigenen Nutzer, Events und Conversions wirklich fließen und wo der Hebel für Optimierung liegt. GA4 ist kein klassisches Analytics-Tool, sondern ein komplexes Daten-Ökosystem, das es zu verstehen gilt – und zwar bis ins letzte Detail.
Der erste Schritt: Verstehen, was GA4 überhaupt ist. Anders als Universal AnalyticsAnalytics: Die Kunst, Daten in digitale Macht zu verwandeln Analytics – das klingt nach Zahlen, Diagrammen und vielleicht nach einer Prise Langeweile. Falsch gedacht! Analytics ist der Kern jeder erfolgreichen Online-Marketing-Strategie. Wer nicht misst, der irrt. Es geht um das systematische Sammeln, Auswerten und Interpretieren von Daten, um digitale Prozesse, Nutzerverhalten und Marketingmaßnahmen zu verstehen, zu optimieren und zu skalieren.... basiert GA4 auf einem Event-basierten Modell, das jedem Nutzer-Interaktionspunkt eine eigene Daten-Unit zuordnet. Diese Events fließen in die Datenströme, die wiederum in Berichte, Audits und Insights münden. Ohne klare Kenntnis dieses Flusses ist jeder Versuch, datengetriebene Entscheidungen zu treffen, töricht. Denn nur wer den Datenstrom durchdringt, kann ihn auch steuern – und so den Data-Driven-Ansatz zum Wettbewerbsvorteil machen.
Das Problem: Viele Marketer und Entwickler verstehen nicht, wie Daten tatsächlich in GA4 ankommen und verarbeitet werden. Sie konfigurieren Events ohne klare Strategie, filtern Daten chaotisch oder lassen wichtige Quellen außen vor. Das Resultat: Verzerrte Reports, falsche Erkenntnisse, und letztlich eine Verschwendung von Ressourcen. Daher ist es essentiell, den Datenfluss zu verstehen – vom Nutzer-Client bis zum finalen Bericht.
Die Architektur von GA4: Datenströme, Events und User Journeys
GA4 arbeitet mit einem modularen System, das auf verschiedenen Datenströmen basiert. Dabei unterscheiden wir primär zwischen App-Datenströmen, Web-Datenströmen und sogenannten hybriden Quellen. Jeder Datenstrom ist eine Art Kanal, durch den Nutzerinteraktionen in GA4 gelangen. Diese Kanäle werden durch die Konfiguration von Events, Parametern und Nutzer-IDs gesteuert.
Im Kern: Jedes Nutzerereignis – sei es ein Klick, eine Seiteview oder eine ConversionConversion: Das Herzstück jeder erfolgreichen Online-Strategie Conversion – das mag in den Ohren der Marketing-Frischlinge wie ein weiteres Buzzword klingen. Wer aber im Online-Marketing ernsthaft mitspielen will, kommt an diesem Begriff nicht vorbei. Eine Conversion ist der Moment, in dem ein Nutzer auf einer Website eine gewünschte Aktion ausführt, die zuvor als Ziel definiert wurde. Das reicht von einem simplen... – wird als Event erfasst. Diese Events sind die Grundbausteine des GA4-Datenflusses. Sie werden durch die Implementierung im Tag-Manager, direkt im Code oder via APIAPI – Schnittstellen, Macht und Missverständnisse im Web API steht für „Application Programming Interface“, zu Deutsch: Programmierschnittstelle. Eine API ist das unsichtbare Rückgrat moderner Softwareentwicklung und Online-Marketing-Technologien. Sie ermöglicht es verschiedenen Programmen, Systemen oder Diensten, miteinander zu kommunizieren – und zwar kontrolliert, standardisiert und (im Idealfall) sicher. APIs sind das, was das Web zusammenhält, auch wenn kein Nutzer je eine... eingespeist. Anschließend durchlaufen sie eine Verarbeitungskette, bei der Parameter angereichert, User-Properties gesetzt und Daten gefiltert werden. Das Ergebnis: eine präzise, granular aufgeschlüsselte Datenbank, die in Dashboards und Reports mündet.
Ein wichtiger Aspekt: Die User Journeys, also die Wege, die Nutzer durch deine Website oder App nehmen. Diese Flows werden in GA4 durch Ereignisse abgebildet, die miteinander verknüpft sind. Das Verständnis dieser Flows ist essenziell, um Schwachstellen im Conversion-Funnel zu identifizieren oder NutzerverhaltenNutzerverhalten: Das unbekannte Betriebssystem deines digitalen Erfolgs Nutzerverhalten beschreibt, wie Menschen im digitalen Raum interagieren, klicken, scrollen, kaufen oder einfach wieder verschwinden. Es ist das unsichtbare Skript, nach dem Websites funktionieren – oder eben grandios scheitern. Wer Nutzerverhalten nicht versteht, optimiert ins Blaue, verschwendet Budgets und liefert Google und Co. die falschen Signale. In diesem Glossarartikel zerlegen wir das Thema... gezielt zu steuern. Hierbei helfen Visualisierungen wie das Nutzerpfad-Report oder Custom Funnels, die auf den Datenströmen aufbauen.
Wie Daten in GA4 fließen: Von der User-Interaktion bis zum Bericht
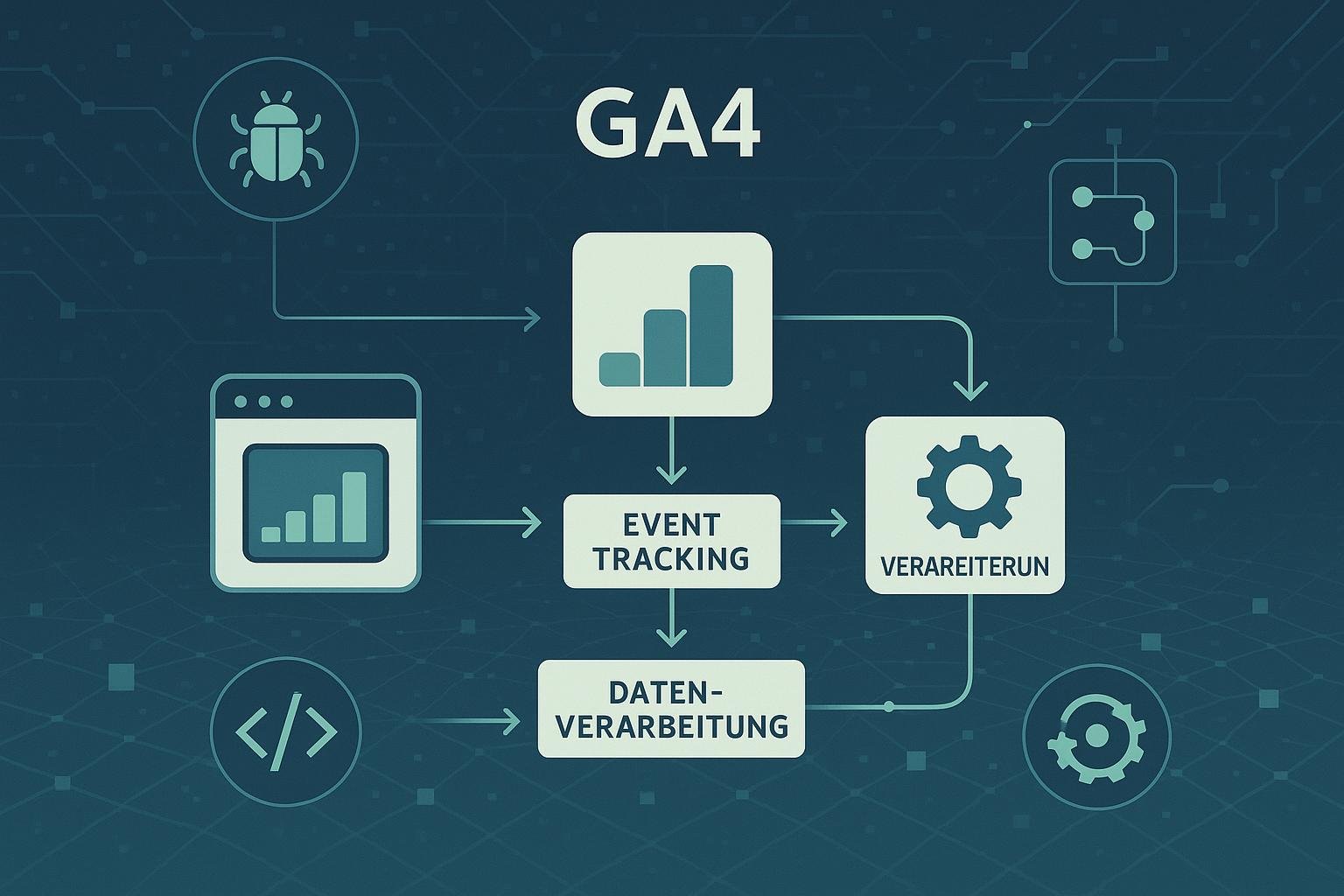
Der Datenfluss in GA4 beginnt bei der Nutzerinteraktion auf der Seite oder in der App. Sobald ein Nutzer eine Aktion ausführt – beispielsweise einen Button klickt – wird ein Event ausgelöst. Dieses Event wird je nach Konfiguration an den Google-Server geschickt, meist über den gtag.js oder den Firebase SDK. Dabei werden Parameter wie Event-Typ, Nutzer-IP, Geräteinformationen und Kontextdaten mitgesendet.
Nach dem Versand gelangen die Daten in die GA4-Processing-Engine. Hier werden sie validiert, gefiltert und angereichert. Dabei greifen Filterregeln, User Properties oder benutzerdefinierte Parameter. Diese Phase ist ausschlaggebend für die Datenqualität: Fehler in der Konfiguration, doppelte Events oder fehlende Parameter führen zu verzerrten Insights.
Im letzten Schritt werden die Daten in die Berichte eingespeist. Hier erfolgt die Aggregation, Segmentierung und Visualisierung. Doch die Daten, die im Report erscheinen, sind nur die Spitze des Eisbergs. Der wahre Wert liegt im Verständnis, wie genau die Daten in den einzelnen Schritten fließen, wo sie eventuell verloren gehen oder verfälscht werden.
Optimale Nutzung der Datenströme: Konfiguration, Debugging und Automatisierung
Der Schlüssel zu effektiven Datenströmen liegt in der richtigen Konfiguration. Das beginnt bei der Implementierung der Events: Jedes Event muss klar definiert, logisch benannt und mit sinnvollen Parametern versehen sein. Hierbei hilft die Planung eines zentralen Tag-Management-Systems, um Fehlerquellen zu minimieren und Datenkonsistenz zu gewährleisten.
Debugging ist unabdingbar: Nutze die DebugView in GA4, um in Echtzeit zu sehen, welche Events ankommen und welche nicht. Hier kannst du Fehler in der Implementierung identifizieren, etwa fehlende Parameter oder doppelte Events. Zudem solltest du regelmäßig die Debugging-Tools im Chrome DevTools nutzen, um den Datenfluss im Netzwerk zu überwachen.
Automatisierung kommt ins Spiel, wenn du wiederkehrende Aufgaben wie Event-Tracking, Daten-Importe oder Berichts-Updates automatisieren willst. Hierfür bieten sich APIs, Cloud Functions oder Data Studio an. Ziel: Weniger Fehler, mehr Kontrolle, bessere Insights. Denn nur wer den Datenfluss automatisiert überwacht, erkennt Probleme, bevor sie zu echten Businessproblemen werden.
Herausforderungen im Data-Flow: Datenschutz, Filter und Datenqualität
Der Datenfluss wird immer wieder durch rechtliche Vorgaben erschwert. Datenschutzbestimmungen wie DSGVO oder CCPA schränken ein, welche Daten du erfassen darfst. Das bedeutet: Du musst den Datenfluss so gestalten, dass er datenschutzkonform bleibt – etwa durch Anonymisierung, Consent-Management oder Data-Filtering.
Zudem führen Filter in GA4 häufig zu Datenverlust oder Verzerrung. Zu aggressive Filter oder falsche Segmentierungen können dazu führen, dass wichtige Nutzergruppen verloren gehen. Hier ist eine klare Dokumentation der Filterregeln unabdingbar, um die Datenintegrität zu sichern.
Qualität ist das A und O: Unsaubere Daten führen zu falschen Entscheidungen. Daher lohnt es sich, regelmäßig Datenintegritätschecks durchzuführen, etwa durch Vergleich mit anderen Systemen oder durch Test-Sessions. Nur so kannst du sicherstellen, dass dein Data-Flow verlässlich und aussagekräftig bleibt.
Tools und Techniken zur Analyse des GA4-Datendurchflusses
Um den Data-Flow sichtbar zu machen, brauchst du die richtigen Tools. Die Google-eigenen Lösungen wie DebugView, Data Stream Reports und die API-Explorer sind erste Anlaufstellen. Damit kannst du in Echtzeit nachvollziehen, welche Events ankommen, wie Parameter verarbeitet werden und wo es zu Dropouts kommt.
Weitere Werkzeuge: Logfile-Analysen, um Server-Requests und Event-Dispatchings zu prüfen. Tools wie BigQuery sind unerlässlich, um große Datenmengen zu aggregieren, zu filtern und tiefgehend zu analysieren. Damit lassen sich komplexe Flows aufsetzen, Muster erkennen und Optimierungspotenziale identifizieren.
Auch externe Monitoring-Tools, die automatisierte Alerts bei Datenverlust oder Abweichungen schicken, sind hilfreich. Ziel: Vollkontrolle über den Datenfluss, um bei kleineren oder größeren Problemen schnell reagieren zu können.
Best Practices: Datenströme für maximale Insights und ROI
Der wichtigste Tipp: Plane deinen Datenfluss strategisch und dokumentiere jede Event-Definition. Nutze Naming-Conventions, klare Parameter-Setups und zentrale Tag-Management-Strategien. So vermeidest du Chaos und hast immer einen Überblick.
Implementiere serverseitiges TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird..., um Datenqualität bei Datenschutz-Constraints zu sichern. Nutze Machine Learning-Modelle, um Anomalien im Datenfluss frühzeitig zu erkennen und zu beheben. Automatisiere Reports und Dashboards, damit du dich auf das Wesentliche konzentrieren kannst: Optimierung.
Vergiss nicht, regelmäßig den Datenfluss zu auditieren. Nutze A/B-Tests, um zu überprüfen, ob Änderungen im TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... tatsächlich den gewünschten Effekt haben. Nur so stellst du sicher, dass dein Data-Ökosystem robust, skalierbar und vor allem: wertvoll bleibt.
Fehlerquellen und Fallstricke: Was deine Daten verfälschen kann
Typische Fehler: Unsaubere Event-Implementierungen, doppelte Events, fehlende Parameter, fehlerhafte Nutzer-IDs, unzureichende Filterregeln oder inkonsistente User-Properties. All diese Faktoren führen zu verzerrten Daten, die im schlimmsten Fall mehr schaden als nützen.
Ein weiterer Fallstrick: Ignorieren des Datenschutzes. Wenn du nicht transparent und verantwortungsvoll mit Nutzerdaten umgehst, riskierst du rechtliche Konsequenzen und Vertrauensverlust. Das wirkt sich langfristig auf den Datenfluss aus, weil weniger Nutzer zustimmen.
Auch technische Fehler wie Server-Timeouts, fehlerhafte Tag-Implementierungen oder unzureichende Cache-Strategien können den Datenfluss beeinträchtigen. Hier ist eine kontinuierliche Überwachung und Wartung notwendig, um eine stabile Datengrundlage zu garantieren.
Zukunftsausblick: Datenarchitekturen 2025 und darüber hinaus
Mit Blick auf die Zukunft wird der Data-Flow noch komplexer. Die Integration von First-Party-Daten, serverseitigem TrackingTracking: Die Daten-DNA des digitalen Marketings Tracking ist das Rückgrat der modernen Online-Marketing-Industrie. Gemeint ist damit die systematische Erfassung, Sammlung und Auswertung von Nutzerdaten – meist mit dem Ziel, das Nutzerverhalten auf Websites, in Apps oder über verschiedene digitale Kanäle hinweg zu verstehen, zu optimieren und zu monetarisieren. Tracking liefert das, was in hippen Start-up-Kreisen gern als „Daten-Gold“ bezeichnet wird... und Data Lakes ist Standard. Die zentrale Herausforderung: eine nahtlose, datenschutzkonforme Architektur, die skalierbar bleibt und Echtzeit-Insights liefert.
Neue Technologien wie Serverless-Architekturen, Event-Driven-Designs und KI-gestützte Datenanalyse werden den Data-Flow revolutionieren. Wer heute schon versteht, wie Daten durch sein System fließen, ist morgen der Gewinner – alle anderen sitzen im Schneegestöber der Datenlawine.
Der gemeinsame Nenner: Daten sind kein Selbstzweck, sondern der Treibstoff für nachhaltigen Erfolg. Wer den Fluss versteht, kontrolliert den Output. Und das ist die einzige Chance, in einem immer schnelleren, datengetriebenen Markt zu bestehen.
Fazit: Nur wer den komplexen Data-Flow hinter GA4 durchdringt, kann ihn auch gezielt steuern und für nachhaltigen Erfolg nutzen. Das ist kein Technik-Fetisch, sondern essenziell für jeden, der im digitalen Business wirklich vorne mitspielen will. Dein Erfolg hängt vom Verständnis deines Datenstroms ab – also mach dich schlau und nutze ihn clever.