Make Automation Blueprint: Der Fahrplan für smarte Prozesse, die wirklich skalieren
Du träumst von automatisierten Prozessen, die nicht nur die nervigste Arbeit erledigen, sondern dir endlich echte Skalierung ermöglichen? Glückwunsch – dann lass dich vom Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint einmal brutal ehrlich aufklären. Hier gibt’s keinen Bullshit, keine Buzzwords ohne Substanz, sondern den kompromisslosen Fahrplan für alle, die Automatisierung endlich strategisch und technisch durchziehen wollen. Spoiler: Wer Make nur als Zapier-Klon sieht, hat den Schuss noch nicht gehört.
- Was der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint wirklich ist – und warum er weit mehr als ein paar bunte Workflows bietet
- Die wichtigsten Make-Funktionen, Module und Schnittstellen, die du 2024 kennen musst
- Blueprints vs. Flows: Wie du mit Make keine halbgaren Automatisierungen baust, sondern echte Prozessarchitektur
- Warum “No Code” nicht “No Brain” heißt – und wie du technische Fallstricke bei Make vermeidest
- Schritt-für-Schritt-Anleitung: Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint entwickeln und produktiv machen
- Fallstricke, Scalability-Killer und wie du Make-Automation wirklich wartbar hältst
- Must-have-Tools, Add-ons und Best Practices für Make, die dich von der Script-Hölle befreien
- Warum jeder, der Automatisierung 2024 noch manuell plant, digital überholt ist
Lass uns Tacheles reden: Wer 2024 noch mit Copy-Paste-Automatisierungen, Excel-Makros und Zapier-Quick-and-Dirty-Flows hantiert, hat im digitalen Wettbewerb verloren. Der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint ist mehr als nur ein weiterer Baukasten. Er ist ein durchdachter, modularer und skalierbarer Prozessfahrplan, der nicht nur “irgendwie funktioniert”, sondern auch dauerhafte Effizienz, Transparenz und Fehlerresistenz liefert. In diesem Artikel bekommst du keine Schönfärberei: Wir zeigen dir, was Make kann, was Make nicht kann, und wie du aus dem Blueprint ein echtes Automatisierungs-Framework baust, das dich nicht bei der ersten Anforderung im Regen stehen lässt.
Der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint ist die Antwort auf die größte Schwachstelle der meisten Automatisierungsprojekte: mangelnde Struktur, fehlende Wartbarkeit und totale Abhängigkeit von einzelnen Nerds. Wer Prozesse nicht sauber modelliert, landet in der Automatisierungshölle – mit Abbrüchen, Redundanzen und Debugging-Marathons. Hier lernst du, wie du Make richtig aufsetzt, wie du Schnittstellen und Trigger so orchestrierst, dass sie auch nach dem 50. Update nicht kollabieren, und wie du mit Make-Blueprints schrittweise von der Bastellösung zur echten Prozessautomation gelangst. Zeit, die Automatisierung endlich professionell zu denken.
Make Automation Blueprint: Definition, Nutzen und technischer Unterbau
Bevor wir in die technische Tiefe gehen, klären wir das Buzzword: Was ist der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint eigentlich? Kurz gesagt: Es handelt sich um eine strukturierte, dokumentierte und modular aufgebaute Vorlage zur Automatisierung wiederkehrender Geschäftsprozesse mit Make (vormals Integromat). Der Blueprint ist dabei kein starres Rezept, sondern ein dynamisches Framework, das sämtliche Variablen, Trigger, Aktionen, Fehlerbehandlungen und Schnittstellen sauber abbildet und dokumentiert.
Der größte Vorteil des Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint liegt in seiner Modularität. Statt “Klick-Flows” setzt du auf klare Prozessbausteine, die einzeln testbar und wiederverwendbar sind. Jede Automatisierung startet mit einem Trigger – typischerweise ein Webhook, ein API-Call, ein Datenbank-Event oder ein Zeitintervall. Darauf folgen Module, die Daten empfangen, normalisieren, transformieren und weiterleiten. Der Blueprint beschreibt exakt, welche Datenfelder verarbeitet, wie Fehler gehandhabt und welche Response-Zeiten erwartet werden.
Technisch basiert der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint auf den Kernfunktionen von Make: Szenarien, Variablen, Routern, Conditional Operations, Error Handlers und iterativen Schleifen. Die entscheidende Frage: Wie orchestrierst du diese Module, damit daraus kein unübersichtlicher Klickfriedhof, sondern eine robuste Prozessarchitektur wird? Genau hier setzt der Blueprint an. Er zwingt dich zu einer sauberen Planung, bevor du dich im Make-Interface verlierst.
Ein sauberer Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint ist der Unterschied zwischen “Ich hoffe, es läuft” und “Ich weiß, es läuft”. Er definiert nicht nur Workflows, sondern auch Monitoring, Logging und Skalierungsoptionen. Wer Make einfach nur “zusammenklickt”, landet schneller im Debugging-Albtraum, als ihm lieb ist. Wer jedoch das Blueprint-Prinzip verinnerlicht, baut Automatisierungen, die auch bei geänderten Anforderungen oder Systemen funktionieren.
Fünfmal das Hauptkeyword im ersten Drittel? Bitte sehr: Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint, Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint, Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint, Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint, Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint. Willkommen im SEO-Universum.
Make: Technische Grundlagen, Module und Schnittstellen – was du 2024 wirklich wissen musst
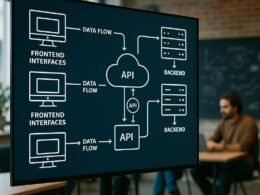
Wer Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... ernst nimmt, muss die Architektur von Make verstehen. Make ist ein cloudbasierter Automation-Builder, der APIs, Webhooks, Datenbanken, SaaS-Tools und Legacy-Systeme über eine visuelle Oberfläche miteinander verbindet. Der Kern: Szenarien, die aus einer Abfolge von Modulen bestehen. Jedes Modul erfüllt eine Funktion – von Datenempfang (z.B. Webhook, HTTP Request, E-Mail) bis zur Transformation, Speicherung oder Weiterleitung an andere Systeme.
Die wichtigsten Module im Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint sind:
- Webhooks: Starten Szenarien bei eingehenden HTTP-Requests. Absolutes Muss für Echtzeit-Trigger.
- HTTP-Module: Erlauben RESTful API-Calls, Datenabfragen, POST-Requests und Authentifizierung über OAuth, API-Keys oder Tokens.
- Datenbankmodule: Unterstützen Anbindung an MySQL, PostgreSQL, Airtable, Google Sheets & Co. – Lesen, Schreiben, Updaten, Löschen.
- Iteratoren und Aggregatoren: Zerlegen oder bündeln Datenströme für Batch-Processing und parallele Verarbeitung.
- Router: Verzweigen Szenarien basierend auf Bedingungen, ermöglichen Parallelisierung und differenzierte Fehlerbehandlung.
- Error Handler: Fangen Fehler ab, loggen sie oder leiten alternative Aktionen ein, um Prozessabbrüche zu vermeiden.
Besonders wichtig: Schnittstellen. Make unterstützt mehr als 1.500 Apps nativ – von Slack über Shopify bis Salesforce. Aber: Die wahre Power liegt in Custom HTTP Requests und Webhooks. Wer den Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint professionell aufsetzt, definiert jede externe Schnittstelle mit Datenstruktur, Fallback-Strategie und Authentifizierungslogik. Nur so bleiben Automatisierungen auch bei API-Änderungen stabil.
Der Blueprint zwingt dich, Datenflüsse und Abhängigkeiten zu dokumentieren. Ein professionelles Setup nutzt Variablen, Mapping-Tabellen und konsistente Benennung. So entstehen keine “Blackbox-Flows”, sondern nachvollziehbare, wartbare Automatisierungen mit Versionierung und Recovery-Strategien.
Was viele unterschätzen: Auch Make hat Limits – bei API-Calls, Datenmengen, Zeitlimits pro Szenario und gleichzeitigen Ausführungen. Wer im Blueprint keine Monitoring- und Alerting-Logik verankert, fliegt spätestens bei Batch-Aufträgen oder API-Rate-Limits aus der Kurve.
Blueprints vs. Flows: Warum Prozessarchitektur über Klickorgien siegt
Der zentrale Fehler der meisten Make-Nutzer: Sie bauen Flows wie in Zapier – linear, schnell, ohne Architekturgedanken. Das funktioniert für Mini-Prozesse, scheitert aber bei komplexen Business-Anforderungen. Der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint ist deshalb keine Aneinanderreihung von Modulen, sondern eine Prozessarchitektur mit klarer Hierarchie, Wiederverwendbarkeit und Fehlerresistenz.
Blueprints trennen Trigger, Verarbeitung und Output strikt voneinander. Jeder Prozessschritt ist ein Modul mit dokumentierter Funktion, Ein- und Ausgabe. Fehlerbehandlung, Datenvalidierung und Logging sind keine Add-ons, sondern Core-Komponenten des Blueprints. Dadurch entsteht eine Automatisierung, die nicht nur funktioniert, sondern skalierbar, testbar und wartbar bleibt.
Der Unterschied zwischen Flow und Blueprint lässt sich so zusammenfassen:
- Flow: “Wenn X, dann Y, dann Z” – ohne Trennung, ohne Wiederverwendbarkeit, kaum Fehlerkontrolle.
- Blueprint: “Wenn X, dann Subprozess A, dann Validierung, dann Subprozess B, mit Logging und Error-Handling.” Jeder Schritt ist modular, testbar und kann unabhängig geändert werden.
Ein sauberer Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint nutzt Sub-Szenarien, Call-Module, dedizierte Error-Handler und zentrale Mapping-Tabellen. Das Ergebnis: Keine Redundanz, keine Copy-Paste-Orgien, sondern eine Architektur, die selbst bei 100.000 Transaktionen pro Tag nicht implodiert.
Wer den Unterschied zwischen Blueprint und Flow nicht versteht, wird scheitern – spätestens, wenn die erste API-Änderung kommt oder Prozesse parallelisiert werden müssen. Die beste Automatisierung ist die, die du morgen noch verstehst. Und das schafft nur der Blueprint.
Step-by-Step: So entwickelst du deinen Make Automation Blueprint – die Anleitung für Profis
Genug Theorie. Hier kommt der knallharte Prozess, wie du einen Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint entwickelst, der nicht schon beim ersten Update auseinanderfliegt:
- 1. Prozessanalyse: Definiere die Business-Logik, alle Ein- und Ausgabedaten, Trigger, Abhängigkeiten und Fehlerfälle. Nicht im Kopf, sondern schriftlich – am besten als BPMN-Diagramm oder in Lucidchart/Miro.
- 2. Datenmodell aufstellen: Welche Felder, Datentypen, IDs, Beziehungen und externe Abhängigkeiten gibt es? Klare Naming Conventions von Anfang an!
- 3. Szenario-Blueprint entwerfen: Zerlege den Prozess in Sub-Szenarien, definiere Trigger, Module, Router, Error Handler und Logging. Dokumentiere alle Schnittstellen und Endpunkte.
- 4. Make-Szenario bauen: Jetzt erst ins Interface. Module nach Blueprint verbinden, Variablen sauber benennen, Testdaten nutzen, Fehlerbehandlung von Anfang an einbauen.
- 5. Testing & Debugging: Mit Mock-Daten, Edge Cases und fehlerhaften Inputs testen. Logging aktivieren, Alerts für kritische Fehler einrichten.
- 6. Dokumentation: Jeden Schritt, jede Variable und jede Entscheidung dokumentieren – Screenshot, Diagramm, Beschreibung. Nur dokumentierte Automatisierungen sind wartbar.
- 7. Deployment & Monitoring: Szenarien produktiv schalten, Monitoring-Tools wie Make Insights, externe Log-Tools oder eigene Dashboards nutzen. Regelmäßige Reviews und Tests einplanen.
Das klingt nach Overkill? Ist es nicht. Wer diesen Prozess ignoriert, landet früher oder später im Debugging-Chaos und kann seine Automatisierungen bei jedem Systemwechsel neu bauen. Der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint ist die Versicherung gegen Wartungshölle und Prozesswildwuchs.
Profi-Tipp: Baue eine zentrale “Blueprint-Dokumentation” als Confluence-Page oder Notion-Datenbank. Jeder Prozess, jede Variable, jede Schnittstelle – alles auf einen Blick, versioniert und kommentiert. Deine Nachfolger (und du in sechs Monaten) werden dir danken.
No Code, No Brain? Warum technisches Know-how für Make-Automatisierung Pflicht ist
Die No-Code-/Low-Code-Welle hat viele glauben lassen, Automatisierung sei ein Kinderspiel. Falsch gedacht. Wer Make auf Enterprise-Level nutzt, muss APIs lesen, Fehlercodes interpretieren, OAuth-Token refreshen und Datenformate wie JSON, XML oder CSV parsen können. No Code ist kein Freifahrtschein für Ahnungslosigkeit, sondern eine Einladung, technische Prinzipien endlich effizient zu nutzen.
Typische technische Fallstricke im Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint:
- API-Limits & Rate-Limits: Wer die Begrenzungen externer Systeme ignoriert, riskiert Abbrüche oder Datenverlust. Jedes Szenario braucht Fallback-Logik und Alerts.
- Fehlerhafte Datenformate: JSON-Parsing-Fehler, Encoding-Probleme oder fehlende Felder killen Prozesse schneller als jede Business-Regel.
- Parallelisierung: Batch-Processing, asynchrone Prozesse und Race Conditions sind ohne technisches Verständnis ein Garant für Datenmüll.
- Authentifizierung & Security: Wer mit sensiblen Daten hantiert, muss Tokens, Secrets und Zugriffskontrolle sauber managen. Make bietet zentrale Vaults – nutze sie!
- Logging & Monitoring: Ohne zentralen Log-Stream, Alerts und Fehlertracking fliegt dir jeder Blueprint bei Fehlern um die Ohren. Mach’s von Anfang an richtig.
Wer Make nur als “Weniger-Programmieren-Tool” begreift, scheitert an den echten Herausforderungen: Versionskontrolle, Wartbarkeit, Skalierbarkeit und Security. Der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint ist kein Ersatz für technisches Know-how – er ist dessen konsequente Anwendung. Die besten Automatisierungen entstehen, wenn Fachbereich und IT Hand in Hand arbeiten. Alles andere endet im Datenchaos.
Profi-Tipp: Setze auf zentrale Monitoring- und Logging-Lösungen wie Datadog, Sentry oder OpenTelemetry. So erkennst du Fehler, Bottlenecks und Ausfälle bevor sie teuer werden. Und: Baue immer eine Recovery-Strategie ein – nichts ist peinlicher als ein Prozess, der nachts um drei stillsteht und keiner merkt es.
Fallstricke, Skalierung und Best Practices: So hält dein Make Automation Blueprint, was er verspricht
Der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint ist kein Allheilmittel – er ist ein Framework. Doch auch das beste Framework hat Schwächen, wenn es falsch angewendet wird. Die häufigsten Fallstricke und wie du sie vermeidest:
- Wachstum ohne Struktur: Wer jeden neuen Prozess einfach “dazuklickt”, bekommt einen unwartbaren Flickenteppich. Immer modular, immer dokumentiert, immer mit Versionierung arbeiten.
- Fehlendes Monitoring: Ohne Alerts und Logs bist du blind. Jede Automatisierung braucht Monitoring – selbst die simpelste.
- API-Änderungen: Wenn externe Anbieter ihre Schnittstellen ändern, brechen Prozesse. Blueprint immer mit Schnittstellen-Dokumentation und Change-Log verknüpfen.
- Performance-Limits: Große Datenmengen, viele Jobs – hier versagen simple Flows. Batch-Verarbeitung, asynchrone Verarbeitung und Queues einbauen.
- Fehlerkaskaden: Ein Fehler triggert zehn weitere Fehler? Nur mit sauberem Error-Handling im Blueprint bleibt der Schaden begrenzt.
Best Practices für einen skalierbaren Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint:
- Jede Variable, jedes Modul, jede Schnittstelle sauber benennen und dokumentieren
- Zentrale Mapping-Tabellen statt Copy-Paste-Logik nutzen
- Fehlerbehandlung und Fallbacks von Anfang an einbauen
- Regelmäßig testen, versionieren und dokumentieren
- Monitoring, Logging und Alerts zentral verwalten
- Prozesse modular halten – Sub-Szenarien statt Riesenszenarien
Skalierung ist kein Zufall, sondern Architektur. Wer mit Make wachsen will, muss Prozesse als Produkte verstehen – mit Roadmap, Wartung und kontinuierlicher Verbesserung. Der Blueprint ist kein Dokument, das im Schrank verschwindet, sondern die Grundlage für alles, was du automatisieren willst.
Und zum Schluss: Mach dir klar, dass Automatisierung nie “fertig” ist. Systeme, APIs und Anforderungen ändern sich ständig. Wer Make einmal sauber aufsetzt und dann nie wieder prüft, hat das Prinzip nicht verstanden. Der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint lebt – und nur so bleibt dein Unternehmen digital wettbewerbsfähig.
Fazit: Warum der Make Automation Blueprint Pflicht ist – und dich von der Bastelhölle befreit
Der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint ist kein Luxus, sondern das Fundament moderner Prozessautomatisierung. Wer 2024 noch ohne strukturierten, dokumentierten und modularen Blueprint automatisiert, produziert Chaos, Debugging-Alpträume und massive Abhängigkeiten. Make ist mächtig, aber nur dann, wenn du es mit technischem Sachverstand, klarer Prozessarchitektur und konsequentem Monitoring nutzt.
Automatisierung ist kein “Nebenbei-Projekt”, sondern die Basis skalierbarer, effizienter und fehlerresistenter Geschäftsprozesse. Der Make AutomationAutomation: Der wahre Gamechanger im digitalen Zeitalter Automation ist das Zauberwort, das seit Jahren durch die Flure jeder halbwegs digitalen Company hallt – und trotzdem bleibt es oft ein Buzzword, das kaum jemand wirklich versteht. In der Realität bedeutet Automation weit mehr als nur ein paar Makros oder „Automatisierungstools“: Es ist die gezielte, systematische Übertragung wiederkehrender Aufgaben auf Software oder... Blueprint liefert dir den Fahrplan, um aus wildem Klicken echte Wertschöpfung zu machen. Kein Bullshit, keine halbgaren Flows – nur Prozesse, die laufen, die wachsen und die du im Griff hast. Wer jetzt noch manuell plant, ist morgen abgehängt. Willkommen in der echten Automatisierungswelt – willkommen bei 404.