

TensorFlow Pipeline: Effiziente KI-Prozesse clever gestalten
Wer glaubt, künstliche Intelligenz wäre einfach ein bisschen Python-Magie plus ein paar Datensätze, hat das Memo verpasst: Ohne eine durchdachte, brutal effiziente TensorFlow Pipeline bist du im Machine-Learning-Zirkus nur der Clown – nicht der Dompteur. In diesem Artikel zerlegen wir den Mythos der “Plug-and-Play-KI”, zeigen dir, warum TensorFlow Pipelines der wahre Gamechanger sind, und liefern dir eine gnadenlose, tief technische Anleitung, wie du aus deinem KI-Workflow endlich mehr machst als akademisches Spielzeug.
- Warum TensorFlow Pipelines das Rückgrat professioneller KI-Prozesse sind
- Die wichtigsten Komponenten, Abhängigkeiten und Begriffe im TensorFlow-Ökosystem
- Wie du mit cleverem Pipeline-Design Datentransformation, Training und Deployment automatisierst
- Fehlerquellen, Bottlenecks und typische Anti-Patterns – und wie du sie vermeidest
- Schritt-für-Schritt-Anleitung zur Entwicklung einer robusten TensorFlow Pipeline
- Unterschiede zwischen TensorFlow, TFX, Keras und Co. – und warum das für dich relevant ist
- Best Practices für Monitoring, Skalierung und Versionierung deiner ML-Pipelines
- Welche Tools, Frameworks und Cloud-Lösungen 2024 wirklich sinnvoll sind
- Ein ehrliches Fazit: Warum KI ohne Pipeline einfach ineffizient und unbrauchbar bleibt
Künstliche Intelligenz klingt sexy. TensorFlow sowieso. Aber wenn du immer noch im Jupyter Notebook hockst, deine Daten per Hand einliest und Modelle manuell trainierst, dann bist du in Sachen KI-Produktivität noch im Hobbykeller. Eine TensorFlow Pipeline ist kein Buzzword, sondern das, was aus deinem Data-Science-Projekt einen skalierbaren, wiederholbaren und wirtschaftlich tragbaren Prozess macht. Genau darum geht es in diesem Artikel: Wir sprechen nicht über Data Science Light, sondern über Engineering, Automatisierung und Operationalisierung – und warum ohne eine durchdachte TensorFlow Pipeline jeder KI-Usecase spätestens beim Deployment kollabiert.
TensorFlow Pipeline ist nicht einfach ein Tool, sondern ein Architekturmuster. Es orchestriert Datenvorverarbeitung, Feature Engineering, Modelltraining, Validierung und Deployment so, dass du Skalierbarkeit, Reproduzierbarkeit und Wartbarkeit bekommst – und nicht nur akademische Proof-of-Concepts. Die Realität im Jahr 2024: Ohne Pipeline kein Wettbewerbsvorteil. Wer ernsthaft KI bauen will, muss sich mit Datenflüssen, Transformationsprozessen, Artefaktverwaltung und Monitoring beschäftigen. Alles andere ist Spielerei.
In den nächsten Abschnitten zerlegen wir das Thema TensorFlow Pipeline auf maximal technische Art: von den Grundlagen über die wichtigsten Module und Patterns, bis hin zu Best Practices für Deployment, Skalierung und Fehlerbehandlung. Schluss mit Marketing-Geschwätz. Hier gibt’s die ungeschminkte Wahrheit, wie du TensorFlow Pipelines wirklich effizient und clever gestaltest – damit dein ML-Workflow endlich Industry-Grade wird.
TensorFlow Pipeline: Definition, Konzept und Hauptkeyword im Fokus
TensorFlow Pipeline ist das Herzstück moderner Data-Science- und KI-Prozesse. Wer TensorFlow Pipeline nicht verstanden hat, kann Machine Learning im produktiven Umfeld direkt vergessen. Das Konzept der TensorFlow Pipeline setzt auf Modularisierung und Automatisierung: Einzelne Schritte wie Datensammlung, Datenvorverarbeitung, Feature Engineering, Modelltraining, Evaluation, Modell-Serving und Monitoring werden als klar definierte, wiederverwendbare Komponenten in einer Pipeline orchestriert.
Der Hauptvorteil einer TensorFlow Pipeline: Sie macht KI-Prozesse robust, skalierbar und nachvollziehbar. Während das klassische Notebook-Chaos irgendwann in einem Code-Sumpf endet, erzwingt die TensorFlow Pipeline einen sauberen, wiederholbaren Ablauf. Daten werden identisch transformiert, Modelle lassen sich reproduzieren, Experimente sind vergleichbar – und Fehlerquellen werden minimiert. Das Zauberwort: Data Provenance. Jeder Schritt, jede Transformation, jedes Artefakt wird dokumentiert, versioniert und kann im Zweifel zurückverfolgt werden.
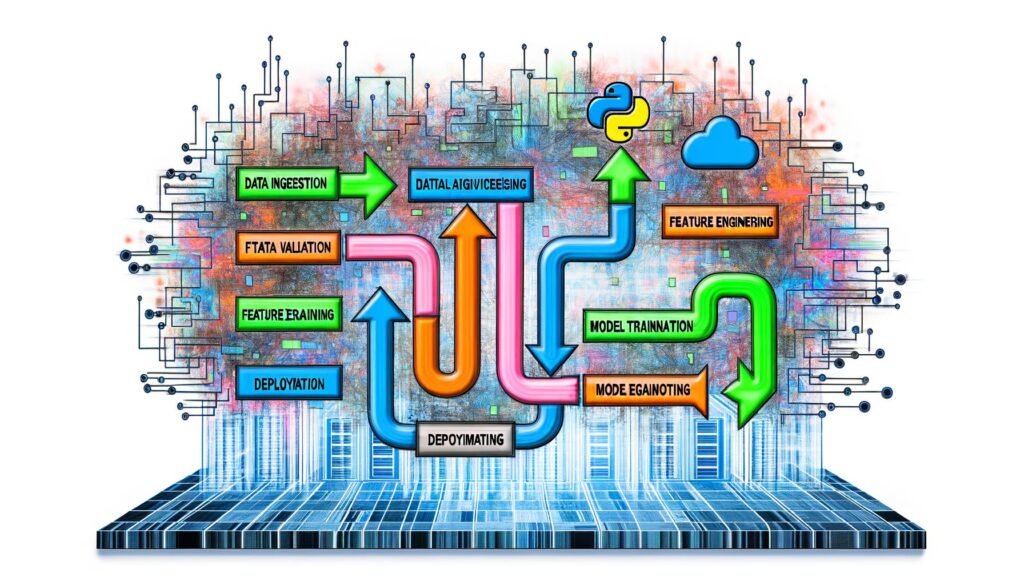
Die TensorFlow Pipeline besteht typischerweise aus folgenden Kernkomponenten:
- Data Ingestion: Automatisiertes Laden und Vorverarbeiten von Rohdaten aus Datenbanken, APIs, Data Lakes oder Flat Files.
- Data Validation: Prüfen der Datenqualität, Typkonsistenz, Wertebereiche – automatisiert und reproduzierbar.
- Feature Engineering: Transformation der Rohdaten in ML-taugliche Features, inklusive Normalisierung, One-Hot-Encoding oder Embeddings.
- Modelltraining: Automatisiertes Training mit TensorFlow oder Keras, inklusive Hyperparameter-Tuning und Cross-Validation.
- Modell-Validation: Statistische Bewertung und Vergleich verschiedener Modelle und Trainingsläufe.
- Model Deployment: Ausrollen des besten Modells in eine Produktionsumgebung – per REST-API, Batch-Job oder Edge-Deployment.
- Monitoring & Feedback: Überwachung der Modellperformance im Live-Betrieb und automatisiertes Retraining bei Drift oder Performance-Degradation.
TensorFlow Pipeline ist damit nicht nur ein technischer Begriff, sondern ein Framework für echte KI-Produktivität. Ohne TensorFlow Pipeline bleibt Machine Learning ein teures Hobby – mit ihr wird es zum Business-Asset. Wer im Jahr 2024 noch manuell Daten verarbeitet und Modelle per Copy-Paste deployed, hat die Zeichen der Zeit einfach nicht verstanden.
TensorFlow Extended (TFX), Keras & Co: Die wichtigsten Tools und Frameworks
TensorFlow allein reicht für produktionsreife KI längst nicht mehr. Das Google-Ökosystem hat deshalb TensorFlow Extended (TFX) geschaffen – die Antwort auf die chaotischen Workflows in klassischen Data-Science-Teams. TFX ist das offizielle Production-Framework für TensorFlow Pipelines, das alle Schritte vom Data Ingestion bis zum Model Serving als orchestrierbare Komponenten abbildet.
Die zentrale Komponente jeder TensorFlow Pipeline im Enterprise-Kontext ist also TFX. Warum? Weil TFX Standardisierung, Wiederholbarkeit und Skalierung garantiert. Pipelines werden als Directed Acyclic Graphs (DAGs) modelliert und können mit Orchestratoren wie Apache Airflow, Kubeflow Pipelines oder Cloud Composer automatisiert werden. Jeder Schritt – z.B. ExampleGen, StatisticsGen, Transform, Trainer, Evaluator, Pusher – ist ein klar gekapseltes Modul mit definierten Ein- und Ausgaben.
Keras ist nach wie vor der Go-to-Ansatz für schnelles Prototyping und Model Building in TensorFlow. Aber: Wer beim Deployment, Monitoring und Skalieren improvisiert, fliegt spätestens beim ersten Retraining aus der Kurve. TensorFlow Serving, TensorFlow Model Analysis (TFMA) und TensorBoard sind weitere zentrale Tools, die in eine moderne TensorFlow Pipeline gehören.
Weitere relevante Technologien für TensorFlow Pipeline:
- Apache Beam: Ermöglicht verteilte, skalierbare Datenverarbeitung als Teil der Pipeline – essentiell bei Big Data.
- ML Metadata (MLMD): Verfolgt Artefakte, Parameter und Pipelineschritte für maximale Nachvollziehbarkeit.
- TensorFlow Data Validation (TFDV): Automatisiert die Datenprüfung und erkennt Anomalien frühzeitig.
- TensorFlow Transform (TFT): Reproduzierbare, skalierbare Feature-Transformation direkt in der Pipeline.
Der Unterschied zwischen einer “Notebook-KI” und einer produktionsreifen TensorFlow Pipeline ist damit kein akademisches Detail, sondern die Basis für alles, was in Unternehmen wirklich funktioniert. Ohne TFX, orchestrierte Pipelines und Monitoring-Tools bist du im Machine-Learning-Zirkus definitiv nicht der Dompteur – sondern die Zielscheibe.
Typische Fehlerquellen und Anti-Patterns in TensorFlow Pipelines
Die Praxis zeigt: Wer ohne klares Pipeline-Design in TensorFlow unterwegs ist, tritt zuverlässig in jede Falle. Die häufigsten Fehlerquellen in TensorFlow Pipelines? Fehlende Modularität, kopierte Transformationen, inkonsistente Datenflüsse, mangelndes Monitoring und Deployment-Flickwerk. Das Resultat: Modelle, die im Live-Betrieb versagen, nicht reproduzierbar sind oder bei jedem neuen Datensatz abstürzen.
Ein oft unterschätztes Anti-Pattern: Feature Drift. Wenn Datenvorverarbeitung und Feature Engineering nicht als Teil der Pipeline versioniert und automatisiert werden, kommt es schnell zu Inkonsistenzen zwischen Training und Inferenz. Ein Klassiker: Training auf bereinigten Daten, aber Serving auf Rohdaten. Das Ergebnis sind fehlerhafte Vorhersagen, die im Zweifel Umsatz kosten.
Ein weiteres Problem: Ad-hoc-Deployments. Wer Modelle per Hand ins Produktivsystem schiebt, vergisst regelmäßig notwendige Preprocessing-Schritte oder überschreibt produktive Modelle ohne Rollback-Möglichkeit. Ohne automatisiertes Modell-Deployment inklusive Validierung und Monitoring ist das reines Glücksspiel – kein Engineering.
Nicht zu vergessen: Skalierungsprobleme. Lokale Pipelines, die auf dem Laptop laufen, brechen bei Big Data und verteiltem Training sofort zusammen. Wer nicht auf verteilte Datenverarbeitung, Containerisierung und orchestrierte Workflows setzt, hat spätestens bei 100 GB Daten das Nachsehen.
Und der Klassiker: Fehlende Artefaktverwaltung. Modelle, Trainingsdaten, Transformationsskripte und Hyperparameter müssen versioniert und dokumentiert werden – sonst ist jede Reproduzierbarkeit Makulatur. ML Metadata (MLMD) ist hier Pflicht, kein Nice-to-have.
Schritt-für-Schritt: So baust du eine robuste TensorFlow Pipeline
Wer eine TensorFlow Pipeline richtig aufbauen will, muss systematisch vorgehen – sonst endet alles im Chaos. Hier ist eine bewährte Schritt-für-Schritt-Anleitung für eine produktionsreife TensorFlow Pipeline:
- 1. Datenquellen anbinden
Definiere, woher deine Rohdaten kommen (SQL, NoSQL, Data Lake, Filesystem). Nutze TensorFlow Data API oderExampleGenin TFX für automatisiertes Data Ingestion. - 2. Daten validieren
Mit TensorFlow Data Validation (TFDV) prüfst du Schema-Fehler, Ausreißer und fehlende Werte. Automatisiere die Datenprüfung als festen Pipeline-Schritt. - 3. Feature Engineering und Transformation
Verwende TensorFlow Transform (TFT), um alle Transformationen (Skalierung, Encoding, Bucketizing) als wiederholbare, versionierte Schritte in die Pipeline einzubinden. - 4. Modelltraining automatisieren
Baue und trainiere dein Modell mit Keras oder native TensorFlow APIs. Integriere Hyperparameter-Tuning (z.B. mit Keras Tuner) und speichere alle Artefakte inklusive Metriken und Konfigurationen. - 5. Modellvalidierung und Vergleich
Nutze TensorFlow Model Analysis (TFMA), um Modelle systematisch zu evaluieren und zu vergleichen. Automatisiere Threshold-Checks für Precision, Recall, F1, etc. - 6. Deployment automatisieren
Verwende TensorFlow Serving, um Modelle als REST-API oder Batch-Job auszurollen. Versioniere Modelle und implementiere Rollback-Mechanismen. - 7. Monitoring und Feedback-Loops
Überwache die Modellperformance mit Monitoring-Tools (Prometheus, Grafana, DataDog) und implementiere automatische Retraining-Trigger bei Performance-Degradation oder Data Drift.
Jeder dieser Schritte ist als eigenständige Komponente in der TensorFlow Pipeline implementierbar und kann mit TFX, Apache Airflow oder Kubeflow automatisiert orchestriert werden. Das Ziel: Kein Schritt bleibt manuell, alles ist nachvollziehbar, skalierbar und robust.
Best Practices für Skalierung, Monitoring und Versionierung von TensorFlow Pipelines
Eine TensorFlow Pipeline, die nur auf dem Laptop läuft, ist wie ein Ferrari im Stadtverkehr – beeindruckend, aber nutzlos. Für echte Skalierung brauchst du Cloud-Integration, verteilte Verarbeitung und konsequente Automation. Die besten TensorFlow Pipelines laufen heute auf Google Cloud Vertex AI, AWS SageMaker oder als Self-Managed-Lösung auf Kubernetes-Clusters mit Kubeflow Pipelines.
Für eine skalierbare TensorFlow Pipeline sind folgende Best Practices essentiell:
- Cloud-native Entwicklung: Setze auf Managed Services für Datenspeicherung, Compute und ML-Workflows. Verzichte auf Bastellösungen und lokale One-Off-Skripte.
- Containerisierung: Packe jede Pipeline-Komponente in einen Docker Container – für maximale Portabilität und Skalierbarkeit.
- Orchestrierung: Nutze Apache Airflow, Kubeflow Pipelines oder Vertex Pipelines, um alle Schritte als DAG zu modellieren und zu automatisieren.
- Monitoring: Überwache nicht nur die Modellperformance, sondern auch Datenqualität, Daten-Drift und Pipeline-Fehler. Automatisiere Alerts und Trigger für Retraining oder Rollbacks.
- Versionierung: Versioniere Daten, Modelle, Transformationen und Konfigurationen mit MLMD oder DVC – für maximale Reproduzierbarkeit und Nachvollziehbarkeit.
Ein echtes Must-have: Automatisiertes End-to-End-Testing der Pipeline. Jede Änderung am Code, an der Datenquelle oder an der Transformationslogik muss in CI/CD-Prozesse integriert werden. Nur so vermeidest du böse Überraschungen beim nächsten Go-Live.
Und: Dokumentation ist kein nettes Extra, sondern Pflicht. Nutze Tools wie TensorBoard, MLflow oder eigens entwickelte Dashboards, um alle Artefakte, Runs und Metriken nachvollziehbar zu machen. Wer nicht dokumentiert, verliert – spätestens beim nächsten Audit oder Data-Drift-Fiasko.
Fazit: Ohne TensorFlow Pipeline keine skalierbare KI
Die Zeit der Data-Science-Bastelbuden ist vorbei. Wer 2024 noch glaubt, mit ein paar Jupyter Notebooks und Copy-Paste-Skripten produktive KI bauen zu können, lebt in einer Parallelwelt. TensorFlow Pipelines sind der Standard für alle, die ernsthaft mit Machine Learning und KI Geld verdienen wollen. Sie machen Prozesse automatisiert, wiederholbar und skalierbar – und genau das ist die Voraussetzung für alles, was nach Proof-of-Concept kommt.
TensorFlow Pipeline ist kein Buzzword, sondern die Basis für effiziente, fehlerfreie KI-Prozesse. Nur wer Pipelines clever plant, modularisiert und automatisiert, bleibt im Machine-Learning-Wettbewerb überhaupt noch relevant. Also: Vergiss Bastellösungen, investiere in saubere TensorFlow Pipelines, und hebe deine KI-Projekte auf das nächste Level. Alles andere ist Zeitverschwendung – und das kannst du dir im Jahr 2024 nicht mehr leisten.